|
|
PLAINセンターニュース第167号 |
|
|
PLAINセンターニュース第167号 |
|
村田 健史 (155号から続く) (番外編) 今回まで、STARS(科学衛星・地上観測データ解析参照システム)の構築過程について紹介してきた。この記事は、(ごく)一部に毎月楽しみにしてくれている読者がいるそうで、できるだけ詳細にその過程について紹介していきたいと思っている。(同様のシステムをこれから構築することを計画している方には、おそらく参考になるであろう。) 時々お休みを頂きながら、約 10 回にわたり STARS 開発の歴史を紹介してきたが、今回、2度目の番外編として、「ペタスケールコンピュータをどう利用するか?」というタイトルでお送りしたい。PLAIN センターは科学衛星観測データセンターであるので、コンピュータシミュレーションは対象外だとお叱りを受けるかもしれない。しかし、いつか本稿でも書くつもりであるが、これからの宇宙科学、特に太陽地球系科学では、科学衛星観測データ解析と計算機シミュレーションはますます切り離せない研究手法となるであろう。科学衛星データから見ても、計算機シミュレーションデータがどのように作られ、どのように利用されるべきであるかは、興味深いテーマである(はずである)。 さて、ペタスケールコンピュータ(以下、ペタコン)は、2010 年ごろに完成する世界最高の処理性能を持つことを目指した 1,000 億円以上の予算をかけた国家プロジェクトである。地球シミュレータは、2002 年〜2004 年にわたり世界最高速スパコンの地位を築いた。(コンピュートニックショックという言葉を耳にしたことがある人も多いだろう。)地球シミュレータは海洋科学研究機構(以下、JAMSTEC)が担当したが、ペタコンは理化学研究所(以下、理研)が担当する。 さて、今回、このタイトルの記事を書くのは、必ずしも偶然ではない。この春(2007年春)に、ペタコンが神戸市のポートアイランドに設置されることが決定した。ポートアイランドは、再生医療やテーラーメイド医療、ナノテクノロジなどの企業が集まる地域クラスタ化が進められており、ペタコンはその中でライフサイエンスやナノテクノロジ分野で国際的・先端的成果が期待されている。しかし、理研の Web サイトで公開さている資料を見ると、宇宙などのフロンティア分野での利用もターゲットテーマのひとつとして考えられているようである。個人的にも、ペタコンがさまざまな宇宙科学分野のコンピュータシミュレーションで利活用されることを期待している。特に、STP 分野は、地球シミュレータプロジェクトでは、現在まで飛躍的な成果を得ることができなかった。ペタコンプロジェクトにおいては、環境、エネルギーなどはもちろん、ライフサイエンスやナノテクにも負けない程の国際的にも評価される成果を期待している。 さて、そのためには、我々には何が必要であろうか?どんな準備をしなくてはならないだろうか? まず、もう一度、ペタコンの規模を考えてみたい。ペタコンは 10 ペタフロップスの演算性能を目指しているわけであるが、これは単純には地球シミュレータの 250 倍の性能である。地球シミュレータの 640 ノード(5120 CPU)というサイズですら「おののいた」私などは、このペタコンがどんな化け物なのか、まだ想像もつかない。しかし、これが「コンピュータのお化け」であることは間違いない。 また、科学技術分野における最近の 1,000 億円以上の国家プロジェクトとしては筑波の加速器や SPring-8 などがあるが、つまりペタコンは誰もが知っているこれらと同じスケールのミッションなのである。この額は宇宙科学研究本部の単一の科学衛星ミッション予算をはるかに上回る額である。もちろん単純な比較はできないが、ペタコンでジョブを打つことは、言い換えると科学衛星に観測機器を搭載するようなものである。 繰り返しになるが、この「例え」が「よい例え」であるかどうかはわからない。しかし、私は、これまでの計算科学研究者(計算機シミュレーションにより科学する人)に最も欠けていたのはこの意識ではないかと思っている。つまり、大規模コンピュータシミュレーションを行うことは、衛星ミッションに観測機器を載せるほどの準備が必要であるという意識である。「大規模シミュレーションと言っても、コードを書いて、並列化(ベクトル化)し、出力データを可視化・解析するだけじゃないか」という意識は、捨てなければならないであろう。 スパコンプロジェクトでは、衛星機器搭載ほどの厳しさの AO(Announce Opportunity)があるわけではない。もちろん、地球シミュレータでのプロジェクト申請でもプロジェクト申請とAOはあったが、主にテーマの有効性とコードのスケーラビリティーなどに重点を置いた評価であった。しかし、ペタコンプロジェクトでは、さらに広い範囲での申請のためのフィージビリティー評価が必要ではないか。
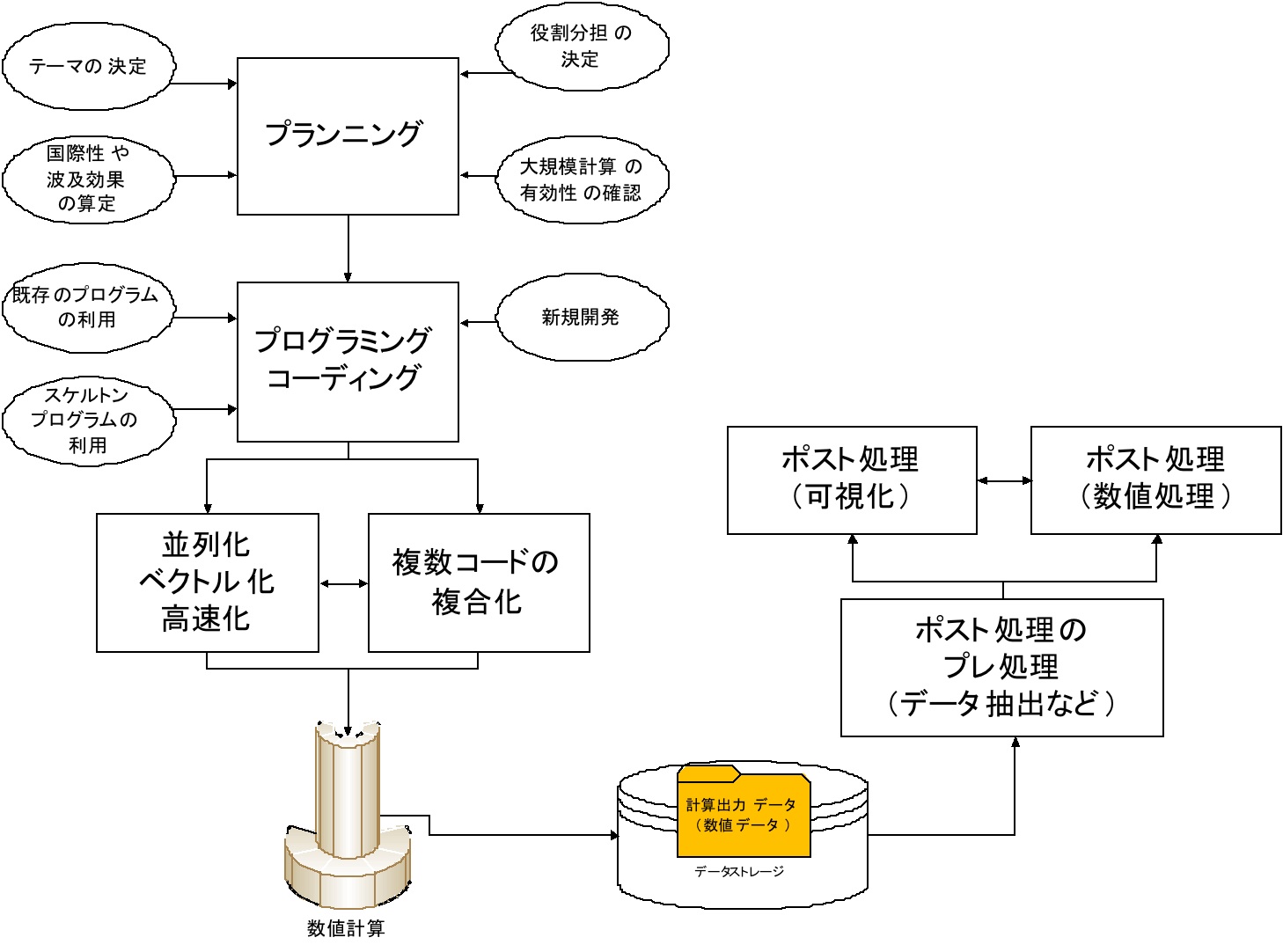
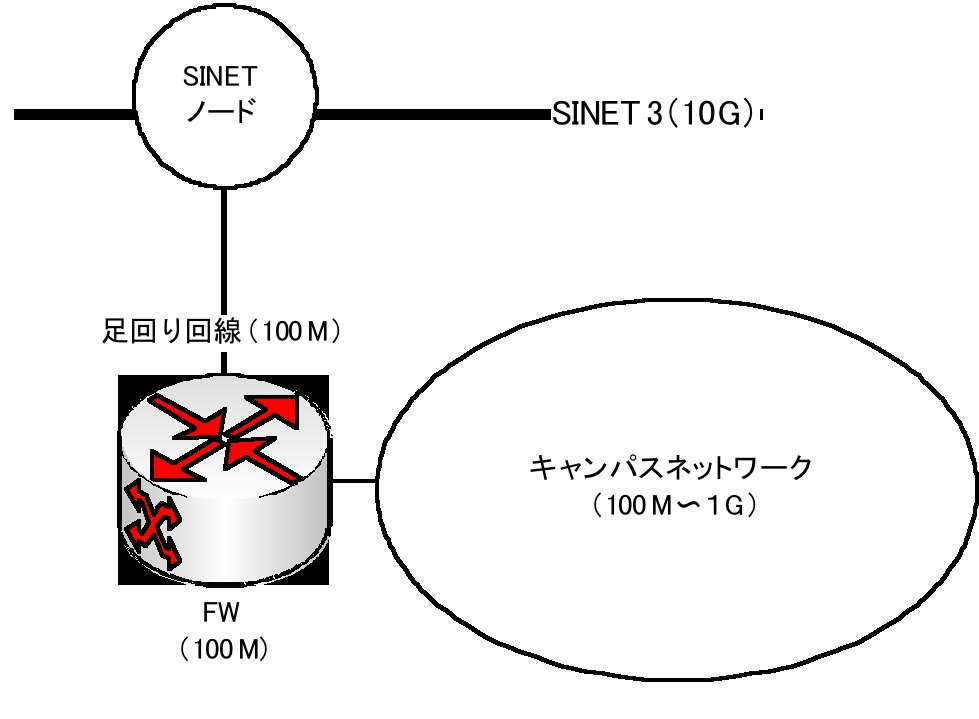
図 20 は、私が提案するペタコンプロジェクトのワークフローである。(これでも、かなりの部分を省略してある。)上記の「コードを書いてデータ処理」という発想では、到底、このお化けコンピュータを使いこなすことができないことがお分かりになると思う。ペタコンはヘテロ環境での最適化された複合シミュレーションを想定しており、我々もそれを活用したい。そのためには、各コードの高速化だけではなく、複合コードの融合技術などが必要である。また、私は不思議なのであるが、多くのシミュレーション研究者は、大規模データをどのようにして自らの研究機関に転送しているのであろうか?愛媛大学(正確には松山 AP)は SINET 3 の 10G ネットワークのノードであるが、データ転送において 10G の恩恵を受けるわけではない。足回り回線が 10G あるとは限らず(愛媛大学は 100 G〜300 G 程度)、また、高速な足回り回線がある場合もファイアウォールによってスループットとしては 100 M から高々 1 G 程度のデータ転送しか期待できないのである(図 21)。この環境を背景にした可視化・データ解析を検討しなくては、「データは作ったが処理ができない」ということも起こりうる。
図 21 SINET3 の 10G ネットワークと FW では、具体的に、どのような問題があり、我々はどのような準備を始めたらよいのか?これについては、次回のこの稿で述べたいと思う。同時に、ペタコンプロジェクトに対する提言もしてみたい。 (次号 に続く)
|
|
|||||||||||