|
|
PLAINセンターニュース第166号 |
|
|
PLAINセンターニュース第166号 |
|
村田 健史 (155号から続く) 前回(5月号:第8回)では、Web Service(WS)によるメタデータ収集システムについて紹介した。今回は、時計を少し巻き戻して、このメタデータ収集システムを WS により設計する前の DBMS(データベース管理システム)の分散データベース機能による STARS 分散メタデータベースについて述べたい。 3.6 STARS 4:分散メタデータベースの重要性(続き) STARS 3 では、メタデータベースを設計・実装することで、STP 観測データ利用者が観測データに自由にアクセスできる仕組みを構築した。STP メタデータとは、データファイル名や観測日時、公開されているデータファイルの URI(Uniform Resource Identifier)などである。(URI とはインターネット上に存在する情報資源の場所を指し示す記述方式であり、インターネットにおける情報の「住所」にあたる。インターネットで広く用いられている URL は URI の機能の一部を具体的に仕様化したものである。) しかし、特定の研究機関や特定の観測データのメタデータベースを構築しただけでは、STARS の本来の目的である「誰もがどの観測データにもシームレスに(つまり、どこに何が管理されているかを意識することなく)アクセスできる」というサービスは実現しない。ユーザがアクセスするメタデータベースは一つであるが、利用できるデータは多くの研究機関のデータであるというのが、STARS の最終目標である。 そこで、STARS 開発グループでは、メタデータを一元的に提供するための統合的メタデータベースを構築することにした。つまり、この統合的メタデータベースに対して検索を行えば、ユーザは STP 分野のあらゆる情報を取得できるわけである。言い換えると、STP メタ情報のポータルサイトを作ろうとしたと考えていただければよい。ポイントは、「ここにアクセスすれば、STP 関係のどのような情報でも取得できるというサービスを実現しようとした」と言うことである。宇宙研などの科学衛星観測機関の重要な責務は、自らの観測データを一般公開することである。私のような利用者は、逆に、宇宙研を含めたあらゆるデータ公開機関のデータを自由に利用したいという希望を持っている。統合的メタデータベースの発想は、このような利用者側の視点から思いついたものである。おりしも、Google をはじめとした Web ポータルサイトが普及しつつあった時期であり、それに触発された部分も大きかったかもしれない。
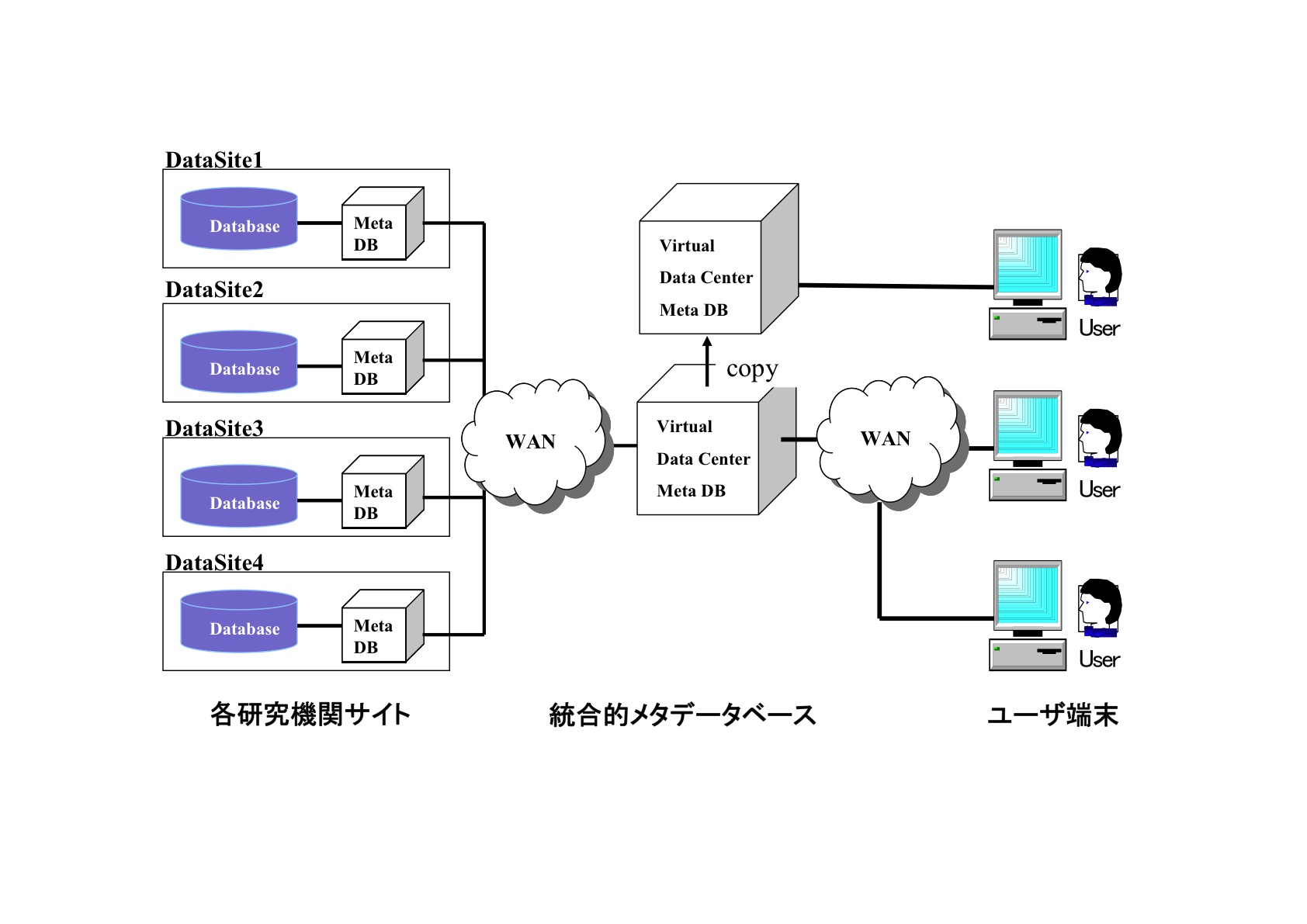
図18 STARS4 で設計したメタデータ利用イメージ 図18 は、当時、修士課程の学生であった呂麗那さん(中国からの留学生)が設計した統合的 STARS メタデータベースのデザインである。左側がデータ提供研究機関であり、例えば宇宙研もこれに該当する。各データ提供機関は、規模はさまざまであるが観測データのデータベースを有している。STARS では、各データ公開機関のデータベースからそれぞれの機関のメタデータを抽出した個別のメタデータベースを作ることにした。メタデータの設計は、STARS3 の項で述べたように設計は終わっていたので、新たに設計をする必要はなかった。 次に、これらのメタデータを収集する仕組みが必要になる。つまり、図18 の統合的メタデータベースである。図にしてしまうと簡単であるが、実際には、この仕組みを実装するのは容易ではない。統合的メタデータベースは、各データ提供機関のメタデータベースと定常的に同期を取り、データを更新しなくてはならない。呂さんと私は、この仕組みを Microsoft 社の SQL Server を使って実現することにした。SQL Server には簡単ではあるが分散データベースのリプリケーション(コピー)などの機能が提供されていたからである。STARS4 では、図18 に示すような統合的メタデータベースのリプリケーションサイトも構築した。リプリケーションサイトは定期的に統合的メタデータベースの全データをコピーすることでプロキシ的な役割を果たすメタデータベースである。これにより、ユーザは自分に最も近い、すなわち高速な検索を行うことができるメタデータベースサーバを選択すればよい。
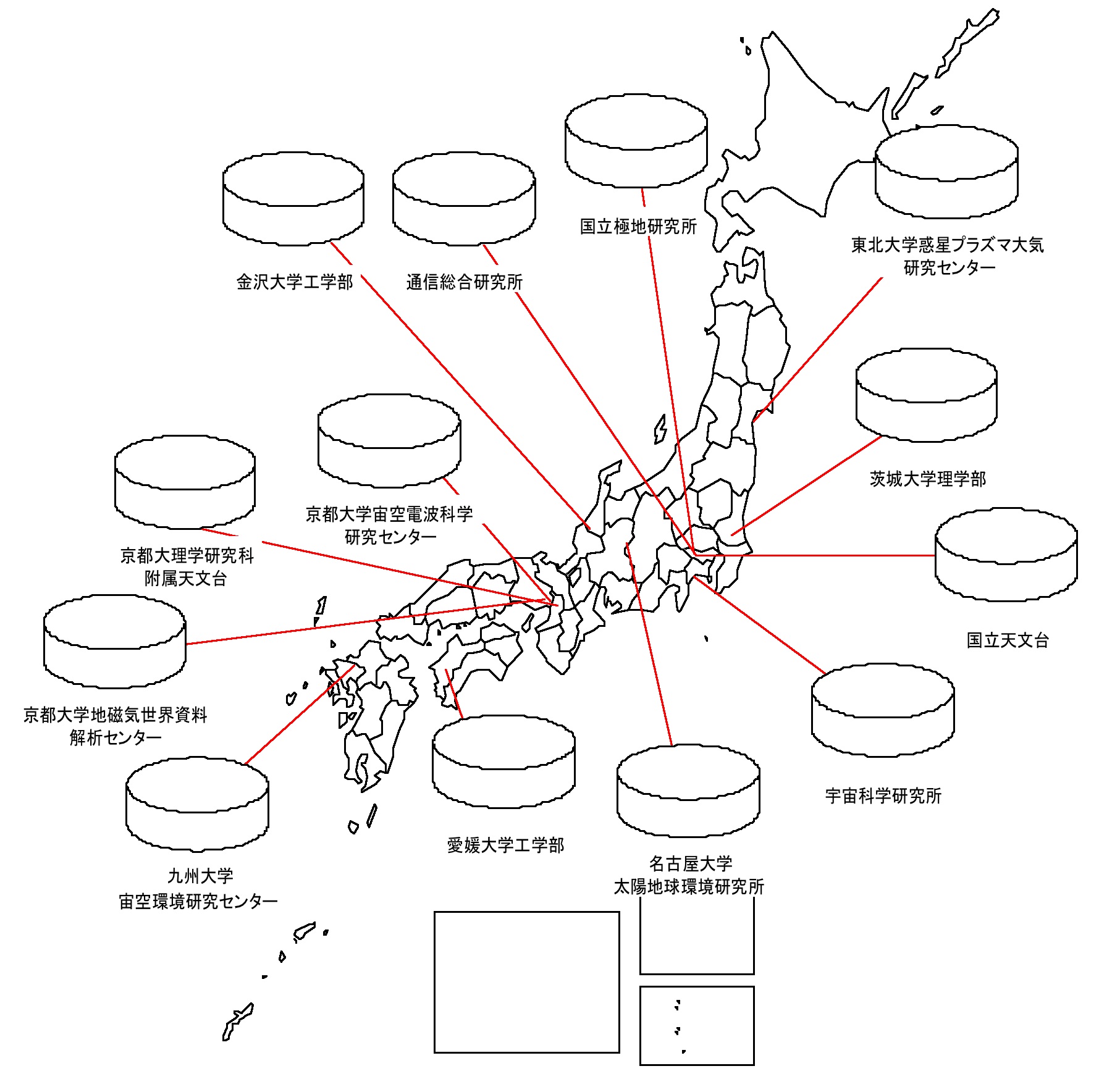
図19 は、図18 の設計によって実際にメタデータベースを構築したデータ公開サイトである。組織名称は、当時のままとした。(組織改革によって、当時から現在までで多くの研究機関の名称が変わったことに、改めて驚いた。)また、図には記載されているが実際にはメタデータデータベースを構築するに至らなかった組織も幾つかある。余談になるが、当時、私の主な研究活動は、データベースの設計や実装をすることではなく、各研究組織のデータ管理担当者と会って相談をすることであった。旅費もままならなかった私は、学会がデータ管理者と打ち合わせをするチャンスであった。セッションにもろくに参加せず、ロビーをうろうろして、データ管理者をつかまえては、メタデータベースを構築させてほしいというお願い事ばかりをしていたような気がする。(ここには名前を挙げませんが、ご協力いただいた各データサイトの管理者の方々、ありがとうございました。) 図19 の各データ公開機関を対象としたメタデータベースは、皮肉にも、対象となる機関が増えるのと並行して、維持運営が難しくなった。当時、各機関のデータ管理者にお願いしてメタデータを作成していただいたのだが、メタデータを手動で定期的に作成するのは、データ管理者への負担が大きかったのである。また、それまでは比較的オープンであったインターネットの世界が、各種のアタックによりファイアウォールを積極的に導入するようになった。特に SQL Server はセキュリティーホールがあったこともあり攻撃の主対象の一つとなり、各研究機関のネットワーク管理者は、こぞって SQL Server のポートを閉じる対応をとった。(しかも、自分の組織が被害者だけではなく加害者にもならないように配慮して、外向き・内向きの両方のポートを閉じることが多かった。) これらにより、図18 のメタデータシステムは、あっさりと運用を断念しなくてはならなくなったのである。私が、「疎結合」と言う言葉を耳にしたのは、それからしばらくしてのことであった。特定の DBMS による分散データベースでは、STP 分野のような独立性の高い複数組織のデータを融合すること、すなわち密結合による分散データベースの実現は難しい。Web Service のように緩やかで柔軟なデータ交換サービスを提供するプロトコルをベースに開発するのが、STP 分野メタデータベースには有効であったわけである。 (次号 に続く)
|
|
|||||||||||