|
|
PLAINセンターニュース第160号 |
|
|
PLAINセンターニュース第160号 |
|
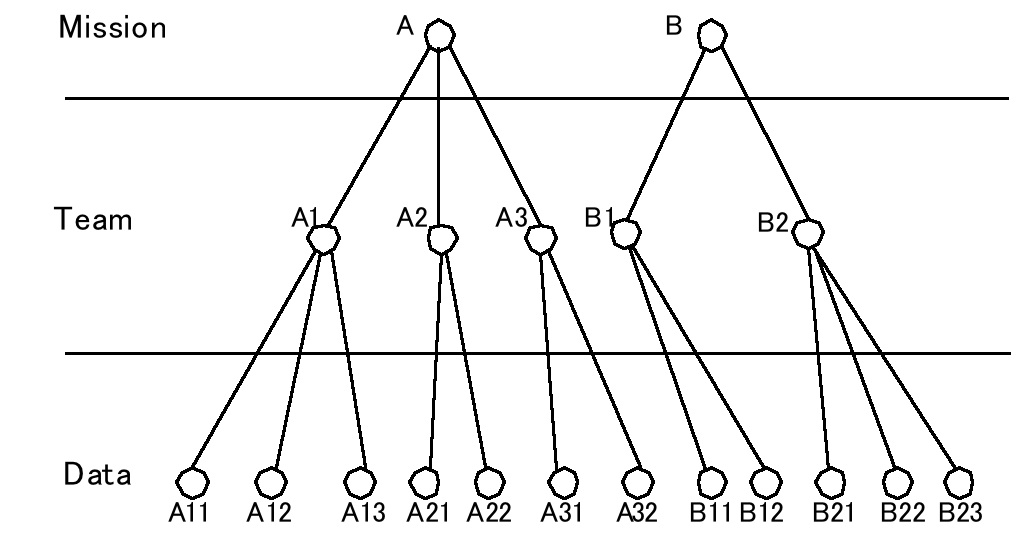
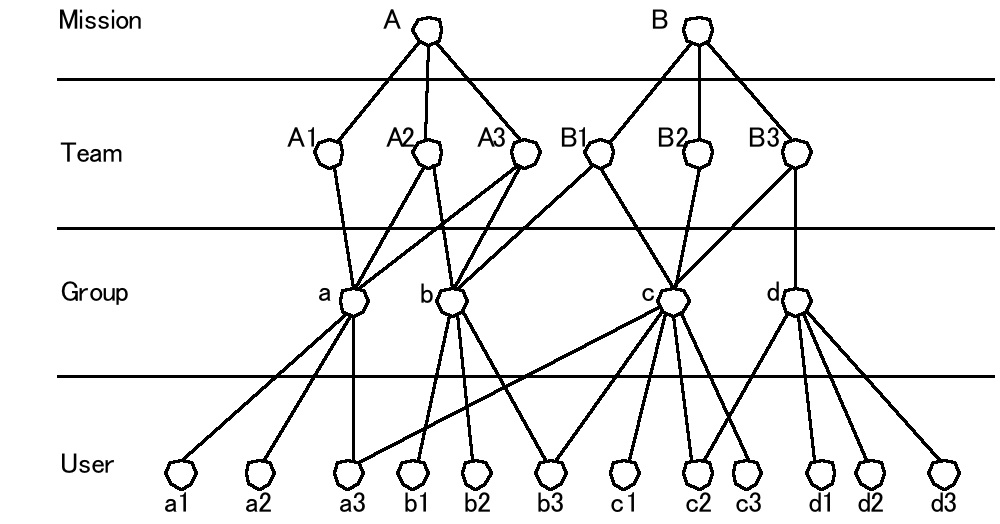
村田 健史 (155号から続く) 3.4 STARS 3:メタデータベースの重要性 STARS1でオブジェクト指向設計開発技法の重要性について述べ、STARS 2 で自己記述型データ構造の重要性について議論した。これらを元により高い情報技術を用いてバージョンアップを行った STARS であるが、依然として利用者数は増えなかった。その一番の理由は、メタデータベースにあった。ここでは、メタデータベースの重要性について議論したい。 自然科学観測分野のデータのデータベースには、大きく分けて二つの種類がある。観測データそのもののデータベース(観測データベース)と、観測データファイルやその他の付随するメタ情報のデータベース(メタデータベース)である。メタデータベースと言う言葉はあまり聞きなれないかもしれないが、その典型が Google のようなインターネット検索サイトである。インターネット検索サイトは、すべての Web ページのデータを保有しているわけではない。インターネットの Web ページについて、ページ内で使われている用語や Web ページの URL(アドレス)など、ページに付随する情報をデータベースとして管理している。ユーザは、まず Google が提供するメタデータベースから必要とするメタ情報を取得し、それを使って目指す Web ページにたどり着き、ほしい情報を収集するわけである。 STP 観測データも多くのメタ情報を持っている。Google と同じように観測データが公開されている URL もメタデータであるが、それだけではない。観測衛星情報、観測機器情報、PI の情報、観測日時、データファイルサイズ、キャリブレーション日時など、観測データファイルには様々な情報が付随している。これらはすべてメタ情報である。メタ情報自身は観測データではないが、観測データを取り扱う際に必要なあらゆる情報が含まれているといってよい。 STARS は、ユーザがデータと観測期間を指定するとその期間のデータをデータファイルから読み出しプロットするツールである。一般的なアプリケーションのようにファイルを指定するとそのファイルからデータを読み出しプロットを作るわけではない。(この方法では、複数のデータファイルによる長期間データプロットが作成できない。)そのため、各データファイルのデータ種類名、観測期間などをメタデータベースとして管理する必要がある。そこで STARS 3 では、メタデータの設計を行うことにした。 メタデータの設計と言うのは、データ解析をする研究者であれば簡単にできそうに思うかもしれないが、実はかなり面倒な作業である。なぜなら、これは、「データを取り巻くあらゆる情報を抽象化し、モデル化する」という作業だからである。たとえば、図12 と図13 は、STARS のメタデータの中心となっているデータおよびデータ利用者(研究者)の所属という概念をモデル化したものである。このモデルでは、簡単に見えるが、実は筆者がこの木構造を設計するために、数ヶ月かかった。たとえば、図12 はデータの所属概念である。 図12 STARS メタデータの例 (1):衛星観測、観測機器、観測データの所蔵概念を木構造で表現した。 図13 STARS メタデータの例 (2):観測計画、観測班、観測グループ、研究者の所蔵概念を木構造で表現した。 これは比較的簡単で、STPミッションではひとつのミッションに複数の観測班が所属し、各観測班が(複数の観測機器により)複数の観測データを出力する。その関係は単純で、上からに下に常に?対多の関係となっている。一方、研究者の所属概念は、それと比較すると複雑である。図13 で研究者の所属を木構造であらわした。たとえば私は、職場では愛媛大学→総合情報メディアセンター →情報基盤部門→村田という所属であるが、データ解析の視点からみると GEOTAIL 衛星→ PWI 班→村田である。しかしこれでは私の学生も GEOTAIL 衛星→ PWI 班→学生となってしまい、私が他の PWI 班の学生を管理したり、その逆になってしまったりすることがある。そこで、STARS ではグループと言う概念を持ち込み、観測班に所属するのは個人ではなくグループ(多くの場合研究室など)であり、個人はグループに所属することにした。また、特定の個人が共同研究などで他の研究室に所属する場合などは、図のグループ c とユーザ a3 のように一時的に他のグループに所属することとした。 このようにして作成したモデルをもとに、メタデータベースを設計した。データベースは、RDB(リレーショナルデータベース)で設計し(図14)、RDBMS(RDB 管理システム)で管理することにした。設計を XML で行いたかったが、当時、XMLDB を管理する DBMS は高額で手が出なかったためである。 図14 STARS メタデータベースのエンディディ図 (次号 に続く)
|
|
|||||||||||