Estimating unknown exoplanet properties using machine learning
Nov. 14, 2024 | GATEWAY to Academic Articles
 Elizabeth TASKER / Department of Solar System Science, ISAS
Elizabeth TASKER / Department of Solar System Science, ISAS
A new extrasolar planet has been discovered! But the detection method has only measured a few of the planet’s properties. Is this world likely to be rocky or gaseous? Could the new planet be a member of a common class of exoplanets, or so rare that it should be the target of follow-up observations by our newest observatories? The answer lies in comparing the new find with the known exoplanet population. But this can be surprisingly challenging.
The exoplanet archive contains the properties of nearly 6,000 discovered planets. However, it is difficult to analyse since almost all planet entries have missing measurements for several properties. This research explored using five machine learning algorithms that could estimate unknown properties of a planet based on the measured values for that planet, and trends identified in the exoplanet archive. Unlike previous work, these codes could all use an archive with incomplete entries, allowing all known planets to be used in the imputation of missing values.
Our favoured algorithm was the “kNNxKDE” that returned a probability distribution for the estimated missing property, rather than a single value. The distribution shape can indicate the certainty of the estimate, whether the planet seems to be rare or unusual compared to the known population, or if multiple values for the unknown property are consistent with the planet’s measured properties, which can highlight features of planet types or evolution.
This analysis can be used to impute missing values to “complete” the archive in order to make further statistical analysis easier, to quantitively see how a new discovery compares to the current exoplanet population, and to examine shapes of distributions to learn more about planet formation.
Research Summary
One of the challenges faced when exploring exoplanet demographics is that factors such as exoplanet’s orbit and size determines which technique can be used for detection. A planet that does not pass between its host star and our view from Earth can never be found via the transit technique, the velocity of a star with a high level of stellar activity can often not be measured accurately enough to pick out the subtle motion due an orbiting planet with the radial velocity technique, while direct imaging is currently only sensitive to massive worlds on distant orbits. These different detection techniques measure different planet properties. The transit technique gives the planet radius, the radial velocity technique provides a minimum mass, while imaging provides a full mass estimate. The result is a vast archive of discovered planets but with many entries that have incomparable properties. Since it’s frequently impossible to observe a planet with multiple detection techniques, even future generations of telescopes will not be able to complete the archive.
The incompleteness of the exoplanet archive usually restricts analysis to identifying 2D trends between pairs of properties in a subset of the planets where both of the two properties are known. The majority of observations (which are both challenging and expensive to collect) are therefore often unused in the formulation of planet formation theories, wasting large quantities of the data and risking mistakes due to the utilized data subset not being representative of the planet population as a whole.
Machine learning has the ability to impute missing values based on a database of currently known examples. One strength is the ability to identify complex trends that depend on multiple properties simultaneously, which is difficult for humans as we typically rely on 2D (or at most, 3D) plots to find patterns. Machine learning can therefore estimate a planet property that cannot be measured through observations by comparing the other properties that have been measured for that planet with trends the code has identified in the exoplanet archive.
However, previous attempts at using machine learning with the exoplanet archive required passing the algorithm a database with no missing properties in which to find trends. This meant that while the algorithm could identify complex trends, these were still based on a small subset of planets which had measured values for all the properties being considered. The risk of drawing conclusions based on a small group of planets therefore persisted.
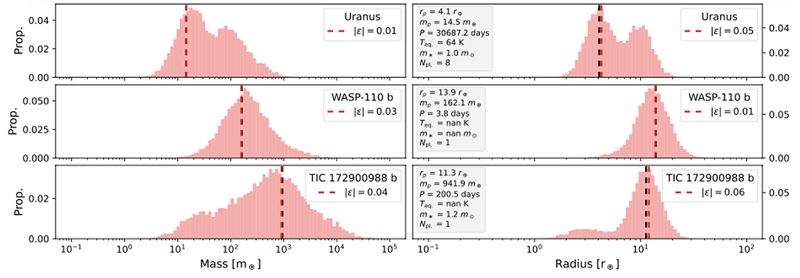
In this work, we tested five machine learning algorithms that could all use a database of entries that contained missing values. This allowed the full exoplanet archive (consisting of over 5,500 planets) to be used to estimate missing planet properties, rather than subsets consisting of only a few hundred planets. In addition, our favored code (the kNNxKDE*1) returned a probability distribution for the estimated value, whose shape contained information about the estimate and the underlying exoplanet population, as shown in Figure 1. For example, a narrow distribution indicated a higher degree of certainty in the result than a broad distribution. In such cases, the planet frequently belonged to a common class of planet, such as the hot Jupiters. Broader profiles indicated that similar planets were rare, and this might be a good candidate for follow-up studies. Alternatively, a broad profile could be divided into distinct peaks. A multi-peak distribution occurs when multiple but distinct values are consistent with the planet’s known properties. For example, planets with two possible masses for a given radius might indicate that both rocky and gaseous planets are possible in this case, or that this type of planet can have an inflated atmosphere.
We focused here on imputing planet mass as a key property that is difficult to measure. However, the algorithms can impute any missing property. While estimating missing values to “complete” the exoplanet archive is useful for later statistical analysis, the distributions returned by the kNNxKDE algorithm for the estimated property is the most valuable use case for assessing new discoveries, and probing details of the known planet population.
Terminologies
- *1 kNNxKDE: an imputation algorithm for estimating missing values that returns a probability distribution for the imputed property. This is a hybrid method using chosen neighbors (kNN) for conditional density estimation (KDE) tailored for data imputation (Lalande and Doya, “Numerical Data Imputation for Multimodal Data Sets: A Probabilisitc Nearest-Neighbor Kernal Density Approach”, Transactions on Machine Learning Research, 2022).
Information
| Journal Title | The Open Journal of Astrophysics |
|---|---|
| Full title of the paper | Estimating exoplanet mass using machine learning on incomplete datasets |
| DOI | https://doi.org/10.33232/001c.124538 |
| Publish date | October 10, 2024 |
| Author(s) | Florian Lalande, Elizabeth Tasker, Kenji Doya |
| ISAS or JAXA member(s) among author(s) | Elizabeth Tasker |
Links
Author

Elizabeth Tasker is an Associate Professor in the Department of Solar System Science at ISAS. Her research looks at the formation and evolution of planets, and she is a science communicator and outreach team member for missions such as Hayabusa2 and MMX, as well as author of the ISAS blog, “Cosmos”.