|
|
PLAINニュース第193号 |
|
|
PLAINニュース第193号 |
衛星データとデータマイニング第2回 データマイニングの実際本田 理恵 1. はじめに 前回 のデータマイニングの概略の説明に引き続き,今回はオープンソースソフトウェアの Weka を用いた学習事例を交えながら代表的な手法について具体的に紹介します。事例としては、はじめての方に衛星データへの活用のイメージをつかんでいただくために、簡潔な例を用いましたが、教科書的記述が多くなってしまったことにはお詫びいたします。また、紙面の制約のため図が小さく見にくくなってしまいましたが,web 版には大きめに掲載されていますのでそちらもご参照ください。 2. 決定木学習 機械学習やデータマイニングでは,“分類”に属する問題が数多く扱われます。“分類“は,複数の属性を持つデータにおいて,ある属性を目的属性,それ以外の属性を従属属性として,従属属性だけから目的属性を決定する問題としてとらえることができます。機械学習の分野では,目的属性をラベルまたはクラス,従属属性をパターンと呼ぶこともあります。 表1に,分類で扱われるデータセットの一例を示します。ここでは,衛星のテレメトリデータを想定して,搭載センサの誤動作の有無,電圧,温度,他のセンサの動作の有無を属性とします 注1。このようなデータセットから,センサの誤動作がおこる条件を知りたい,という要求があるものとします。この場合,衛星の誤動作の有無を目的属性,それ以外を従属属性とすることになります。 表1 データセットの一例センサ誤動作情報ー
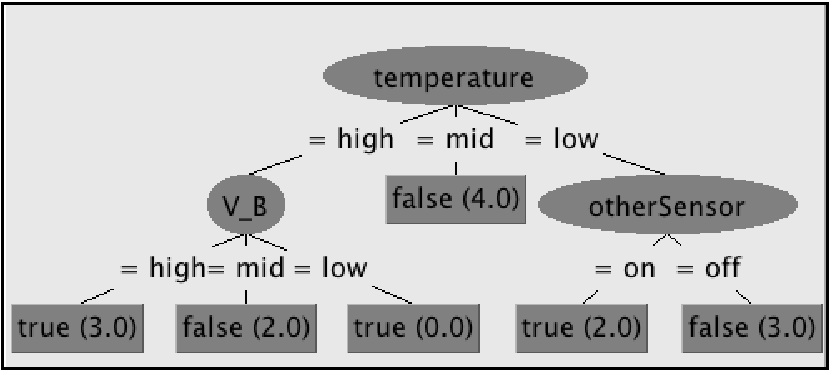
“分類“を扱う手法には,ナイーブベイズ,サポートベクターマシンなど種々のものがありますが,ここでは決定木学習を取り上げます。表1のデータに対して求められた決定木の例を図1に示します。決定木の根または節には従属属性に対する条件式が割り当てられます。一方,葉には目的属性が割り当てられます。よって,目的属性の値が未知で従属属性が既知のデータが与えられた場合,従属属性の値を参照しながら決定木を根から葉へたどっていくことによって,この事例の目的属性値を推定することができます。
このような木構造を,データからの学習によって形成しようとするのが決定木学習です。決定木学習では,まず全データに対して考えられる全ての分割条件を用いてそれぞれ分割を試行し,目的属性に関しての分割前と分割後のデータセットの多様性指標の変化量を計算します。ここで,多様性指標の減少量がもっとも大きくなる条件を最初の分割条件として採用してデータセットを分割します。この過程を分割後の各データセットが目標属性について均一になるか,それ以上の分割条件がなくなるまで再起的に実施していきます。多様性指標には様々な物が有りますが,代表的なアルゴリズムである Quinlan の C4.5 や C5.0 では情報エントロピーに基づく情報利得比が用いられています。 また,木構造は,if then 形式のルールで表現することもでき,このルール自体が現象に関する知識であって,決定木学習によってこの知識を発掘することができた,と解釈することもできます。図1の決定木では,“if temperature=high and V_B=high then sensor failure=true, if temperature = low and otherSensor=active then failure=trueとなり,このセンサが不具合を起こすのは,温度が高く B点の電圧が高いとき,または,温度が低く他のセンサが動作しているとき,ということになります。 3.相関分析 発生した事象の共起関係を調べたい場合には相関分析が有用です。相関分析は,トランザクションに現れるアイテム間の共起関係を分析します。顧客の購買分析とのアナロジーで説明すると,トランザクションは顧客の買い物籠(バスケット),アイテムはバスケットにはいった商品としてとらえることができます。 このようなデータから相関ルールと呼ばれる共起関係を抽出します。相関ルールは A→B という形で表記され,A という事象が発生すれば高い確率で B という事象も発生することを示します。相関ルールの重要性の指標には支持度 (support),確信度(confidence)があります。Support (A→B) は全トランザクション数に対する A と B が共起するトランザクション数の割合を表し,confidence (A→B) は A を含むトランザクション数に対する A と B が共起するトランザクション数の割合を示します。よって confidence (A→B) と Support (A→B) が大きいルールが重要なルールということになります。 ルールの抽出にあたっては,アイテムの数が増加することによって組み合わせ数が膨大になって計算が困難になるという問題がありますが,IBM アルマディン研究所の Agrawal によって開発された Apriori アルゴリズムによって大規模データから効率よくルールを抽出することが可能になっています。 4.クラスタリング この他,一般的な用途によく用いられる手法としてクラスタリングがあります。クラスタリングは,数値やカテゴリ値からなる多次元ベクトルを対象とし,類似度に基づいたグループ分けを行う手法です。数値属性のベクトルについては,類似度の代わりに相違度としてベクトル間のユークリッド距離がよく使用されます。クラスタリングは,決定木学習のようにあらかじめ目標属性のようなお手本が与えられないため,教師無し学習の一つです。 具体的な手法には,階層的な手法と非階層的な手法があります。階層併合的クラスタリングは,1データを1クラスタに割り当てた状態を初期状態とし,データを相違度の小さいものから順番に併合して最終的に一つのグループになるまで反復します。併合過程のデータ集合をまとめたデータ集合は樹状図をなし,様々な階層レベルでグループを評価することができます。 一方,非階層的な手法には K-means 法などがあります。K-means 法ではあらかじめグループの個数 k を定め,K 個のクラスタの重心の初期値をランダムに与えます。次に各データについて,全てのクラスタ重心との距離を計算して最も距離のクラスタにデータを割り付けます。全てのデータの割り付けの完了後,各クラスタの属するデータセットからクラスタの重心を決定し直します。この過程を決められた回数,またはデータの重心の変化がなくなるまで反復することによって,尤もらしいグループ分けを得ることができます。 K-means 法は非常に明快なアルゴリズムですが,K をあらかじめ与えなければならない,初期値によって結果が大きく異なる,といった欠点も持ちます。使用時にはこうした特徴に対する注意が必要です。 この他,多変量正規分布の混合モデルでの近似もよく用いられます。学習(パラメータ推定)には EM アルゴリズムが用いられます。 なお,数値属性データではクラスタリングの実施前に,異なる属性値間の寄与を等しくするために各属性の間で正規化を行うことが必要な場合も有ります。 5.Weka によるデータマイニング実例 それでは前回紹介したニュージーランド大で開発されたデータマイニングや機械学習のための統合的ソフトウェア Weka を使用して,前述の代表的な手法によるデータの学習の実例を紹介します。 インストール データの準備 ヘッダ部の @relation の後にはテープルの名前を,@attribute の後には属性の名前とタイプを記述します。カテゴリ値の場合は {high, mid, low} のように列挙して示します。数値属性の場合は,”@attribute temperature numeric”のように記述します。なお,数値属性のタイプには real, integer, numeric を指定することができます。データ部はデータ毎に各行に記述された“,”で区切られた属性値の羅列であり,CSV ファイルのフォーマットと同じとなっています(属性値の順番はヘッダに記述された属性の順番に従います)。よって,CSV ファイルの先頭にヘッダを不可するだけで,入力ファイルを簡単に作成することが可能です。
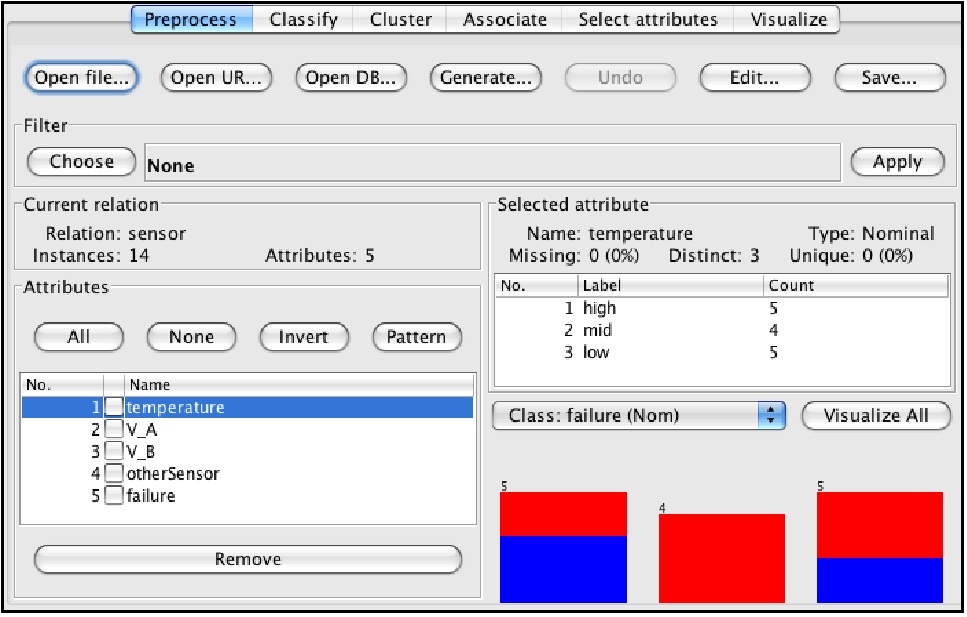
図2 入力用データ sensor.arff の例(ARFF形式) 起動 データ読み込み 図3 に読み込み直後の画面を示します。この画面ではデータの属性や分布についての特徴が表示されます。右下に表示されたヒストグラム左上のリストで目標属性(クラス)を選択して,右側の”visualize all”ボタンをクリックすると,各属性値のデータに占める目標属性値(クラス)毎のデータ分布を,色付きヒストグラムで一覧することができます。
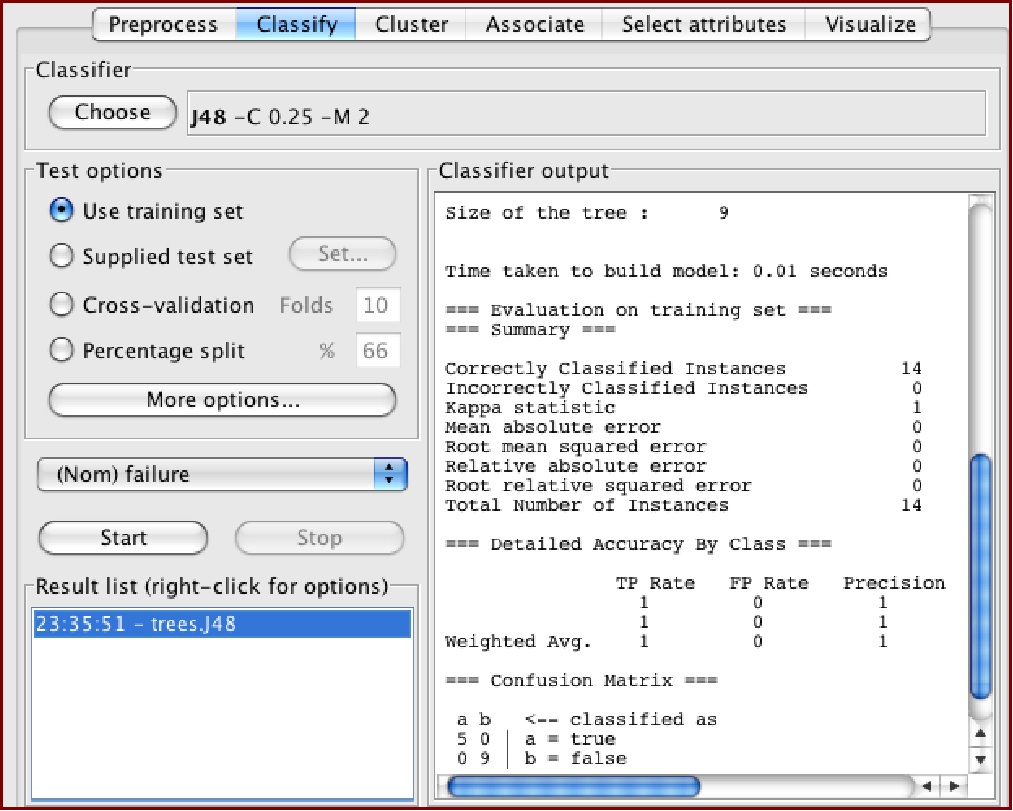
決定木学習 左側の”Test option”では学習の方法として交叉検定法などが選択できますが,ここではひとまず全データを使用して学習を行う”Use training set”を選択します。詳細なオプションはその下の”More options”で指定することができます。また,その下のリストで,目的属性を選択します。ここではセンサの誤動作を示す“failure”を選択します。 次にその下側にある”Start”ボタンをクリックすると学習が開始されます。学習結果は得られた決定木に対する評価値とともに右側のウィンドウに表示されます。得られた決定木の尤もらしさは,TP(true positive rate), FP rate (false positive rate), precision, recall などで表示されます。詳細は省略しますが,この場合の正答率は 100% で性能のよい決定木が得られたことになります。 なお,作成された決定木を可視化するには,左下の学習結果のリスト“Result list”に追加された計算結果のリストを右クリックして “Visualize tree”を選択すると,図1のような決定木が別のウィンドウに表示されます。
相関分析 最上段の”Associate”をクリックして相関分析用のウィンドウに切り替えます。次の段の”Associator”をクリックして “apriori”を選択します。”apriori……”と表示されたリストの欄をクリックすると,抽出時の support の敷居値などを設定することができます(デフォルトでは 0.2)。“Start”ボタンを押すと計算が実行され,右ウィンドウに以下のような抽出された相関ルールが表示されます。なお,上記のルールの確信度は1,支持度は 14/3 で重要性の高いルールといえます。
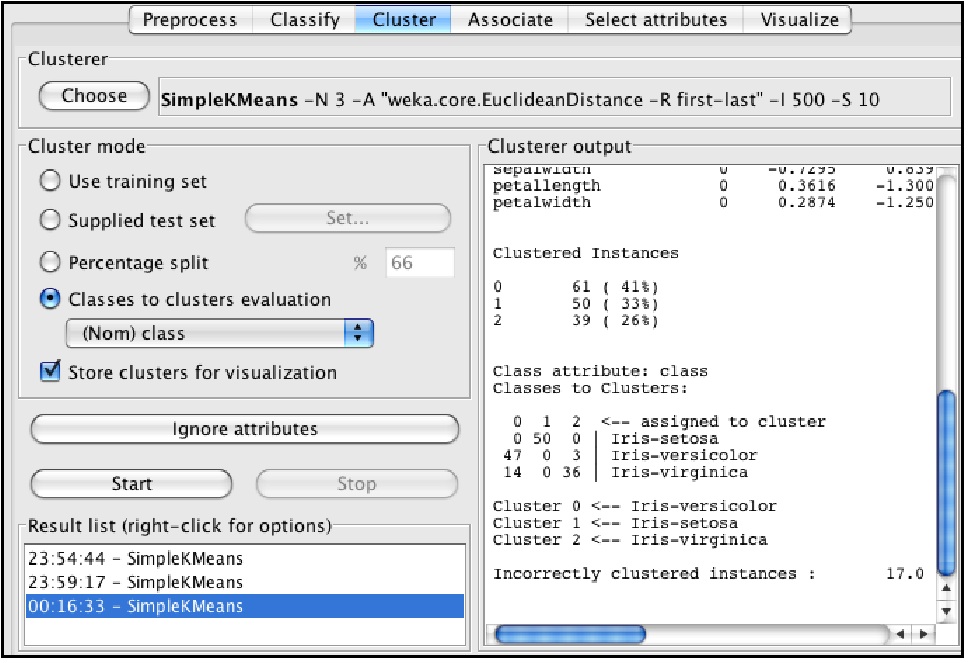
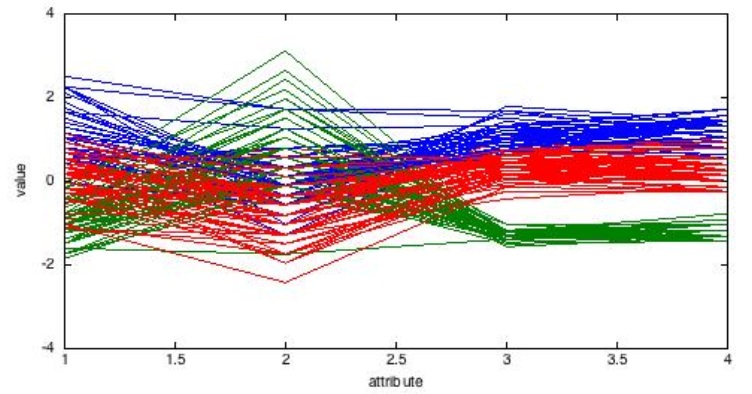
クラスタリング まず”Preprocess”ボタンを押して,”Open file”で data の“iris.arff”を指定します。数値属性の場合,必要であれば前処理を実施します。属性ごとの正規化を実施するには,Filter 欄の“Choose”ボタンを押して,filters,unsupervised, attribute を順に指定して,”standarize”を選択し,”apply”ボタンを押します。これによって,各属性値は属性毎に 0 を平均値として標準偏差が1になるように正規化されます。 次に最上部の”Cluster”ボタンをおして,図5 のクラスタリング画面に切り替え,“Choose”からアルゴリズムを選択します。ここでは簡単のため”simpleKmeans”を選択します。選択したアルゴリズムが表示されているリスト欄をクリックするとクラスタ数(numClusters, k)などのパラメータを入力することができます。今回はデータセットの記述からアヤメの種類が 3個であることが既知なので,numClusters=3 とします。また,学習の際にアヤメの種類をマスクしてクラスタリング結果と比較するために,左側の Cluster mode から“Classes to clusters evaluation”をクリックして,リストで class(アヤメの種類)を指定します。 Start ボタンをクリックすると処理が始まり,右画面にその結果が表示されます。最下部に表示された各データのクラスタ番号とマスクしたアヤメの種類の比較結果から,誤分類は 17/150,11%で,教師データを与えなくても,まずまずのグループ化ができたたことがわかります。 なお,”Result list” を右クリックして,”visualize cluster assignments”を指定すると,属性毎のクラスタ分布が可視化されます。データ毎のクラスタリング結果を見るには,この画面の save ボタンをクリックして保存用のファイル名を指定してエクスポートします。 図6 にクラスタリングの結果をクラスタ毎に色を変えたスペクトル形式で表示してみます(エクスポートしたデータからプロット)。この図からもスペクトルの形状に応じた自動的なグループ化がなされていることを見て取ることができます。
6.まとめ 今回は代表的な3つの手法,決定木学習,相関分析,クラスタリング(k-means 法)について,toy data に対して Weka を使用した分析例を含めながら説明しました。使用したデータはまさに”toyーおもちゃ”レベルですが,ここで取り上げたような分析のニーズは,様々なシチュエーションで頻出するものであると考えられます。データマイニングは知識の発見という大きな目的を目指すものではありますが,分析指針が定まらず眠っているデータや,煩雑な手作業の自動化などにも活用可能ですので,お試しいただけると幸いです。 次回 は,少し進んだモデルや,実際の活用例などについて紹介する予定です。
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||