|
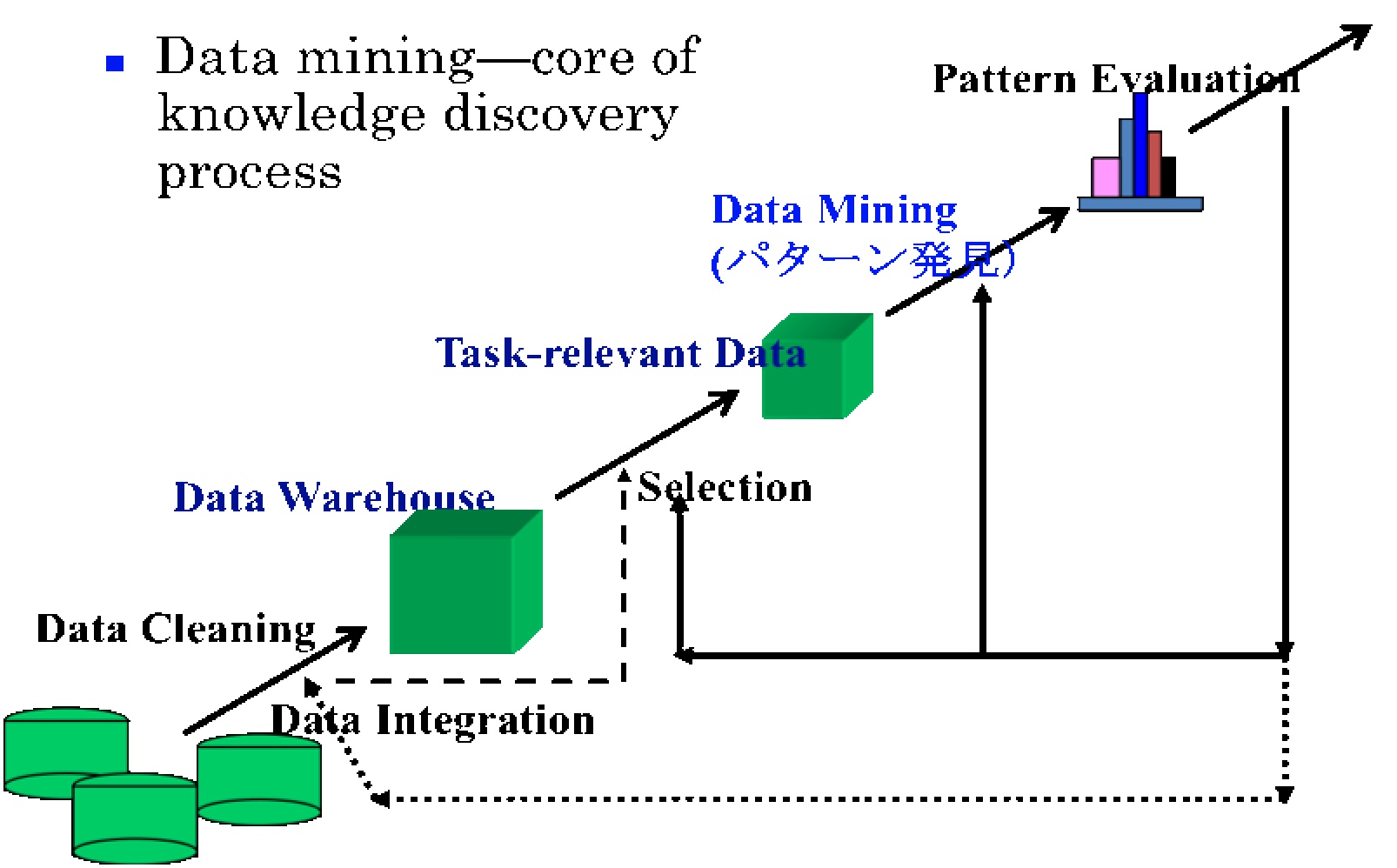
衛星データとデータマイニング第1回 データマイニングとは本田 理恵 1. はじめに 今回から 3 回にわたり、データマイニングとその衛星データへの応用について紹介していきます。筆者は情報科学分野のデータマイニングや機械学習の手法を衛星データからの知識発見に適用する研究を行っています。きっかけとなったのは 1990 年代後半の月周回衛星探査計画 SELENE(かぐや)プロジェクトの開始でした。4TB を超える月のデータをわずか1年の間に日本の科学衛星で取得する、という内容は当時の想像をこえるもので、大量データn効率的解析手法についても新しい枠組みで検討しなければならないと実感させられました。2007 年 9月に種子島から打ち上げられた”かぐや”は、2009 年 6月 11日に無事その任務を終え、テラバイト級の巨大な月のデータが今や現実のものとなり、11月から一般へのデータ公開も開始される予定です。 また、宇宙科学の分野でもスローン・デジタル・スカイ・サーベイ (http://www.sdss.org) や Virtual Observatory(http://www.ivoa.net , http://jvo.nao.ac.jp)などのプロジェクトで、テラバイト級の観測データベースが提供されてきています。このような状況は我々がこれまでに経験したことのないものであり、従来主流であった仮説検証型の研究手法に加えて、サーベイ型の観測データを前提にその量を質にかえるような新たな解析手法を模索する時期にも来ていると考えられます。 その一つの取り組みが情報分野のデータマイニングや、機械学習などの手法の適用です。これらはデータからの新しい知識取得の支援や、大量のデータの要約、カタログ化、意味付けをして可用性を高めることに適用可能であり、データが大規模化すればするほど重要になると考えられます。 本稿ではこのような状況をふまえて、データマイニングの紹介からはじめて、科学衛星データへの適用例や、実際に小規模な実験を試すことのできるツールの紹介、そしてデータセンタとの関わりについても述べていきたいと思います。 2. データマイニング、機械学習 1990 年代、ストレージや CPU などの低価格化と高性能化、データベース管理システムやインターネットの普及により、様々な分野で大量のデータが蓄積されるようになりました。一方で、データ量の増大に対して人間による処理が追いつかず、データが増えるほど逆に得られる知識の割合が少なくなることが懸念されました。このような背景のもとに 1990 年代半ばから十数年ほどの間に急速に発展したのがデータマイニングの研究分野です。 データマイニング (data mining) とは、大量のデータからコンピュータを用いて有用な知識を発掘 (mining) しようとする実用志向の技術の総称で、統計学、データベース、情報検索、人工知能分野の機械学習などの分野を源流として発展してきています。特に、機械学習 (machine learning) は、コンピュータが課題解決能力を自ら学習していくために必要なメカニズムを解明することを目的とした学問領域で、決定木学習などのデータマイニングの多くの重要なアルゴリズムがこの分野からもたらされています。 データマイニングは KDD (Knowledge Discovery from Database:データベースからの知識発見) という呼び方で呼ばれることもあります。初期のデータマイニングの発展を牽引した Fayyad によれば、知識は、妥当(たまたま見つかったものではない)で、新規性、有用性があり、かつ理解可能であるパターンであり、この考えは一般的に受け入れられています1。 図1に知識発見のプロセスを示します2。知識発見のプロセスは、大きく分けて、前処理、パターン発見、後処理から構成されます。前処理には、元になるデータベースの統合、不適当なデータの削除や形式の統一などのデータ洗浄、データウェアハウスの構築などが含まれます。さらに、構成されたデータウェアハウスから、パターン発見のタスクに関連のあるデータを選択して学習用のデータセットとする過程が続きます。中心プロセスであるパターン発見では、次節で紹介するような手法を用いて、データから様々な形式のパターンの発見を行います。後処理では得られたパターンを評価し基準を満たしたものを知識として抽出します。なお、この過程は1回限りのプロセスではなく、あらゆる過程において期待する成果が得られなければそれ以前のプロセスにも戻って改善の上試行を繰り返します。厳密には、この知識発見の全過程を KDD と呼び、この中のパターン発見のプロセスだけをデータマイニングと呼びます。しかし、実際には前処理や後処理(特に前処理)の過程が結果を大きく左右するため、実用では全過程を視野に入れた検討を行うことが必須となります。
図1 知識発見のプロセス2 3. データマイニングのタスクと手法 データマイニングの代表的なタスクには、分類、クラスタリング、相関分析、回帰などがあります。これ以外にも統計学的なモデリングなどの高度なタスクが存在します。また、データを記述すること自体を目的とする場合と、得られた知識やパターンから予測を行うことを目的とする場合、その両方を目的とする場合があります。 分類はデータの属性からクラスを決定するもので、その手法には決定木学習、ルール学習、ナイーブベイズ学習、最近傍法、ニューラルネットワーク、サポートベクトルマシンなどがあります。分類すべきクラスと属性の両方が既知のデータを用いて学習を行うため、このような手法は機械学習の分野では、教師あり学習と呼ばれるジャンルに属します。 一方、クラスタリングはデータを複数の属性からなる多次元ベクトルとみなし、属性空間の中に分布するデータから特徴の似通ったものを塊(クラスタ)として検出しようとする手法です。クラスタリングの手法には大きく分けて階層的な手法と非階層的な手法があります。一般的に、クラスタリングはデータだけから手本なしに学習を行う教師なし学習のジャンルに属するものととらえることができます。 相関ルールは "Aであれば Bも高い確率でおこる" というルールで、これをデータ集合から見つけ出すのが相関ルール分析です。A, B には現象や属性値の組み合わせをとりうるため、属性数の多い問題に対しては組み合わせ爆発により分析困難となりますが、ア・プリオリをはじめとする効率的なアルゴリズムの開発により、大量データに対しても適用が可能になっています。 また、これらの汎用的なアルゴリズムに加え、取り扱うデータの種類によって特化される時系列データのマイニング、画像や動画のマルチメディアデータマイニング、グラフ構造のマイニング、テキストマイニングなどのカテゴリも存在します。 なお、これらの代表的な手法で行うような処理は、科学的データ分析でも初期段階において一般的に実施されるものであり、大量データに対する科学的発見の支援にも有効と考えられます。4. データマイニングのソフトウェア 前説で述べた代表的な手法の多くは商用ソフトウェアやフリーソフトウェアなどで利用することができます。このようなソフトウェアの情報は Kddnuggets(http://www.kddnuggets.com)などのサイトで調べることができます。オープンソースフリーソフトウェアとしては、ニュージーランドの Waikato 大学で開発された Weka(http://www.cs.waikato.ac.nz/ml/weka)がよく知られています。Weka には、前処理、代表的な手法によるパターン発見、評価、そして、データや分析結果の可視化の機能が実装されています。また、使用形態もグラフィカルユーザーインターフェースによる対話的処理、コマンドラインベース処理、Java コードからの参照などをサポートし、ソースコードも公開されていますので、最初に各種のアルゴリズムによるデータマイニングを体験するには最適なソフトウェアの1つです。 ただし、利用にあたってはデータマイニングの諸過程の様々な手法がどのような原理でどんな効果があるのか理解していることが必要になりますので、現時点で興味を持たれた方は、一度、包括的な教科書(例えば3)に目を通した上でソフトウェアを使用ください。5. まとめ 今回は、データマイニングとは何なのか、代表的な手法とソフトウェアにはどんなものがあるか、といったことについてその概略を紹介しました。次回以降は、個別の手法・具体的な適用例について述べていく予定です。 参考文献
|
|
||||||||||||