|
|
PLAINƒjƒ…پ[ƒX‘و197چ† |
|
|
PLAINƒjƒ…پ[ƒX‘و197چ† |
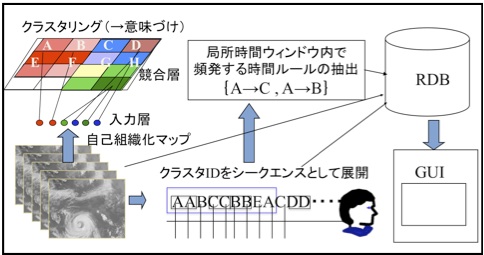
‰qگ¯ƒfپ[ƒ^‚ئƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‘و‚R‰ٌپ@ƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جٹˆ—p—ل–{“c —Œb 1.پ@‚ح‚¶‚ك‚ة پ@ 2009”N‚XŒژ‚©‚çٹJژn‚µ‚½–{کAچع ‚àچإڈI‰ٌ‚ئ‚ب‚è‚ـ‚µ‚½پBچ،‰ٌ‚ح‰qگ¯ƒfپ[ƒ^‚ض‚جƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚ض‚جٹˆ—p—ل‚ًڈذ‰î‚µ‚ـ‚·پB‰qگ¯‚ة‚و‚ء‚ؤژو“¾‚³‚ê‚éƒfپ[ƒ^‚ة‚حپC•،گ”‚ج‘®گ«‚ًژ‚آگ”’lپCƒJƒeƒSƒٹ’lƒfپ[ƒ^پCژŒn—ٌƒfپ[ƒ^پi‘½ژںŒ³پjپCƒXƒyƒNƒgƒ‹پi‘½ژںŒ³پjپC‰و‘œپiƒ}ƒ‹ƒ`ƒ`ƒƒƒ“ƒlƒ‹پjپCژŒn—ٌ‰و‘œپi“®‰وپj“™‚ھ—L‚èپCƒfپ[ƒ^‚جŒ`ژ®‚ئ–ع“Iپiƒ^ƒXƒNپj‚ة‚و‚ء‚ؤ“K—p‚·‚éژè–@‚ً‘I‘ً‚·‚邱‚ئ‚ة‚ب‚è‚ـ‚·پBچ،‰ٌ‚ح‰qگ¯ƒfپ[ƒ^‚ة“ء—L‚جپiژŒn—ٌپj‰و‘œپCƒXƒyƒNƒgƒ‹‚ة‚آ‚¢‚ؤپC•Mژز‚ئ‹¤“¯Œ¤‹†ژز‚ھچs‚ء‚½Œ¤‹†‚ً’†گS‚ةˆµ‚ء‚ؤ‚¢‚«‚ـ‚·پB‚ب‚¨پCڈذ‰î‚·‚éژ–—ل‚ة‚ح’n‹…ٹد‘ھ‰qگ¯‚ج—ل‚ھ‘½‚ٹـ‚ـ‚ê‚ـ‚·‚ھپC‰F’ˆ‰بٹwƒfپ[ƒ^‚ة‚¨‚¢‚ؤ‚à‹¤’ت‚·‚é–â‘è‚ً‘½‚ٹـ‚ق‚½‚كپCˆê”تگ«‚ً‘¹‚ب‚¤ژ–‚ح‚ب‚¢‚ئچl‚¦‚ؤ‚¢‚ـ‚·پB‚ـ‚½پCژہ—ل‚إ‚حپC‘O‰ٌ‚ـ‚إ‚ةڈذ‰î‚µ‚½‘م•\“I‚بژè–@‚¾‚¯‚إ‚ب‚‘½—l‚بژè–@‚ھ•،چ‡“I‚ةژg—p‚³‚ê‚ؤ‚¢‚ـ‚·‚ج‚إپCڈ‰ڈo‚جژè–@‚ة‚آ‚¢‚ؤ‚ح‚»‚ج“s“xٹب’P‚بڈذ‰î‚ً‰ء‚¦‚ؤ‚¢‚ژ–‚ة‚µ‚ـ‚·پB 2پDژŒn—ٌ‹Cڈغ‰و‘œ‚ة‘خ‚·‚éƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO پ@•Mژز‚جڈٹ‘®‚·‚éچ‚’m‘هٹw‚إ‚ح 1996 ”Nˆب—ˆپC“Œ‹‘هٹwگ¶ژY‹ZڈpŒ¤‹†ڈٹپC‹Cڈغ‹ئ–±ژx‰‡ƒZƒ“ƒ^پ[“™‚©‚ç”zگM‚³‚ꂽ‹Cڈغ‰qگ¯‰و‘œ‚ذ‚ـ‚ي‚è5چ†پiGMS5پj,GOES, ‚ذ‚ـ‚ي‚è6چ†پiMTSATپj‚ج“ْ–{ژü•س‚ج‰و‘œ‚ًƒAپ[ƒJƒCƒu‚µ‚ؤ‚¢‚ـ‚· [1]پB–{گك‚إ‚ح‚±‚جƒfپ[ƒ^‚ًƒeƒXƒgƒxƒbƒh‚ئ‚µ‚ؤژہژ{‚³‚ꂽ‚R‚آ‚جŒں“¢ژ–—ل‚ة‚آ‚¢‚ؤڈذ‰î‚µ‚ـ‚·پB 2.1 ƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ئژٹش‘ٹٹضƒ‹پ[ƒ‹‚ج’ٹڈo پ@‰نپX‚ھ‹Cڈغ‰و‘œپi ‰_‚ةٹ´‰‚·‚éIR‰و‘œپj‚ًٹدژ@‚·‚é‚ئ‚«پCپg“TŒ^“I‚ب‰ؤ‚ج‰و‘œپhپCپg”~‰J‚جژٹْ‚ج‰و‘œپhپCپg“~‚ج‰و‘œپh‚ب‚اپCŒoŒ±‚ة‚و‚ء‚ؤ“ء’¥‚ة‰‚¶‚½‰و‘œ‚جƒ^ƒCƒv‚ً”»’f‚·‚éژ–‚ھ‚إ‚«‚ـ‚·پB‚±‚ج‚و‚¤‚بƒ‰ƒxƒ‹•t‚¯‚ًژ©“®“I‚ةŒvژZ‹@‚ةژہژ{‚³‚¹‚ؤ‘ه—ت‚جژŒn—ٌ‰و‘œ‚ً‹Lچ†Œn—ٌ‚ة•دٹ·‚·‚邱‚ئ‚ھ‚إ‚«‚ê‚خپC‚»‚±‚©‚çژٹش•د“®‚جƒpƒ^پ[ƒ“‚ب‚ا‚ج’mژ¯‚ً’ٹڈo‚·‚éژ–‚ھ‚إ‚«‚é‚ئٹْ‘ز‚³‚ê‚ـ‚·پB پ@گ}‚P‚حپC‚±‚جƒ^ƒXƒN‚ج‚½‚ك‚ةٹJ”‚µ‚½ƒVƒXƒeƒ€‚جٹT—v‚إ‚· [2][3]پB‚ـ‚¸“ء’¥‚ة‰‚¶‚½‰و‘œ‚جƒ‰ƒxƒ‹•t‚¯‚ًچs‚¤‚½‚ك‚ة‰و‘œڈWچ‡‚ة‘خ‚µ‚ؤƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ًژہژ{‚µ‚ـ‚·پB‚±‚جچغپC‰_‰ٍ‚جˆت’u‚ة‚ح‚±‚¾‚ي‚炸پCپg‘ن•—‚ئ‘Oگü‚ًٹـ‚ق‰و‘œپh‚ئ‚¢‚ء‚½‰و‘œ‚جˆس–،‚إ‘ه‚ـ‚©‚ةƒOƒ‹پ[ƒv‰»‚·‚邽‚ك‚ةپC‚Q’iٹK‚جƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ًژہژ{‚µ‚ؤ‚¢‚ـ‚·پB‚ـ‚¸پC‰و‘œ‚ًƒuƒچƒbƒN‰»‚µپCƒuƒچƒbƒN–ˆ‚ج“ء’¥ƒxƒNƒgƒ‹پi‹P“xƒxƒNƒgƒ‹پC‚ـ‚½‚ح FFT ƒpƒڈپ[ƒXƒyƒNƒgƒ‹پj‚ة‘خ‚µ‚ؤƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ًژہژ{‚µ‚ـ‚·پB“¾‚ç‚ꂽŒ‹‰ت‚©‚ç‚P–‡‚ج‰و‘œ’†‚ةٹـ‚ـ‚ê‚éƒuƒچƒbƒN‚جƒNƒ‰ƒXƒ^‚ة‚آ‚¢‚ؤ‚ج•p“x•ھ•z‚ً‹پ‚كپC‚±‚ج•p“x•ھ•z‚ً‰و‘œ‚ج“ء’¥ƒxƒNƒgƒ‹‚ئ‚µ‚ؤپCچؤ“xƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚ـ‚·پBچإڈI“I‚ة“¾‚ç‚ꂽƒNƒ‰ƒXƒ^‚حپC‰و‘œ’†‚ةٹـ‚ـ‚ê‚é‘ن•—‚â‘Oگü‚ب‚ا‚ج—جˆو‚ھ‚µ‚ك‚é–تگد‚ة‚و‚ء‚ؤƒOƒ‹پ[ƒv•ھ‚¯‚³‚êپC‚»‚ꂼ‚ê‚ج‘ن•—‚جˆت’u‚ب‚ا‚ة‚ح‰e‹؟‚ًژَ‚¯‚ب‚¢ژ–‚ة‚ب‚è‚ـ‚·پB
پ@ƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚جŒ‹‰تپCژŒn—ٌ‰و‘œ‚ح (A,A,A,A,B,B,A,Cپc) ƒNƒ‰ƒXƒ^ƒ‰ƒxƒ‹‚جژŒn—ٌ‚ة•دٹ·‚³‚ê‚ـ‚·پB‚±‚±‚©‚çپgA ‚جŒم‚ة‚ح B ‚ھ”گ¶‚·‚éپhپCپgB ‚جŒم‚ة‚ح C ‚ھ”گ¶‚·‚éپhپC‚ئ‚¢‚ء‚½ƒ‹پ[ƒ‹‚ً’ٹڈo‚·‚é‚ة‚حپC‘و‚Q‰ٌ‚ةگà–¾‚µ‚½‘ٹٹضƒ‹پ[ƒ‹‚ة—قژ—‚µ‚½ژè–@‚ً—p‚¢‚éژ–‚ھ‚إ‚«‚ـ‚·پBژŒn—ٌ‚جژٹش‘‹‚ًƒoƒXƒPƒbƒgپCژٹش‘‹’†‚ةکA‘±‚µ‚ؤ‘¶چف‚·‚éƒNƒ‰ƒXƒ^ƒ‰ƒxƒ‹‚ًƒAƒCƒeƒ€پiƒCƒxƒ“ƒgپj‚ئŒ©‚ب‚µ‚ؤپC‘ٹٹضگ«‚جچ‚‚¢ƒ‹پ[ƒ‹‚ً’ٹڈo‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB‚ـ‚½پC‚±‚¤‚µ‚ؤ’ٹڈo‚³‚ꂽƒ‹پ[ƒ‹‚âƒNƒ‰ƒXƒ^ƒ‰ƒxƒ‹پC‰و‘œ‚ًƒfپ[ƒ^ƒxپ[ƒX‚ةٹi”[‚·‚邱‚ئ‚ة‚و‚ء‚ؤپCƒ†پ[ƒUپ[‚ھ‘خکb“I‚ةچ‚ژں‚ج’mژ¯”Œ©‚ًژx‰‡‚·‚邱‚ئ‚à‰آ”\‚ئ‚ب‚é‚ئچl‚¦‚ç‚ê‚ـ‚·پB پ@‚ب‚¨پCڈم‹L‚جژè–@‚جƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ة‚ح‚Q‘w‚جƒjƒ…پ[ƒ‰ƒ‹ƒlƒbƒgƒڈپ[ƒN‚ج‚Pژي‚إ‚ ‚é Kohonen ‚جژ©Œب‘gگD‰»ƒ}ƒbƒv (self organizing map, SOM) [4] ‚ً—p‚¢‚ؤ‚¢‚ـ‚·پBSOM ‚ح–{چe‚إڈذ‰î‚·‚鑼‚ج–â‘è‚إ‚à—ک—p‚³‚ê‚ؤ‚¨‚èپC‹³ژtƒfپ[ƒ^‚ھ‚ب‚¢ڈَ‘ش‚إپC‘ه—ت‚جƒfپ[ƒ^ڈWچ‡‚ج“à—e‚ً—‰ً‚·‚é‚ج‚ة”ٌڈي‚ة—LŒّ‚بژè–@‚إ‚·‚ج‚إ‚±‚±‚إڈذ‰î‚µ‚ؤ‚¨‚«‚ـ‚·پB پ@SOM ‚حگ}‚P‚جچ¶ڈم‚ج—ھگ}‚ج‚و‚¤‚ةپC“ü—حƒxƒNƒgƒ‹‚ًژَ‚¯ژو‚é“ü—ح‘w‚ئ‚QژںŒ³‚جƒ†ƒjƒbƒgƒAƒŒƒC‚©‚ç‚ب‚é‹£چ‡‘w‚©‚ç‚ب‚èپC‹£چ‡‘w‚جٹeƒZƒ‹‚ح“ü—حƒfپ[ƒ^‚ئ“¯‚¶ژںŒ³‚جƒxƒNƒgƒ‹‚ً‹L‰¯‚µ‚ؤ‚¢‚é‚à‚ج‚ئ‚µ‚ـ‚·پBڈo—ح‘w‚جٹeƒ†ƒjƒbƒg‚جڈ‰ٹْ’l‚ً—گگ”‚إ—^‚¦‚½ŒمپCٹe“ü—حƒxƒNƒgƒ‹‚ة‘خ‚µ‚ؤچإ‚àژ—’ت‚ء‚½ƒxƒNƒgƒ‹‚ًژ‚آ‹£چ‡‘w‚جƒ†ƒjƒbƒg‚ًپgڈںژزƒ†ƒjƒbƒgپh‚ئ‚µ‚ؤپCٹwڈKƒfپ[ƒ^‚ًٹ„‚è•t‚¯پC‚»‚ê‚ئ“¯ژ‚ةڈںژزƒ†ƒjƒbƒg‚جƒfپ[ƒ^‚ًٹwڈKƒfپ[ƒ^‚ة‹ك‚أ‚¯‚ـ‚·پB‚±‚جچغپCڈںژزƒ†ƒjƒbƒg‹ك–T‚جƒZƒ‹‚àژم‚ٹwڈK‚³‚¹‚邱‚ئ‚ة‚و‚ء‚ؤپC‹£چ‡‘w‚ح“ü—حƒxƒNƒgƒ‹‚ج•ھ•z‚ًڈ™پX‚ةٹwڈK‚µپC‹£چ‡‘wڈم‚إ‹ك‚¢ˆت’u‚ةژ—‚½“ء’¥‚ھ”z’u‚³‚ê‚é‚و‚¤‚ة‚ب‚è‚ـ‚·پB پ@SOM ‚ح–{—ˆƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ً–ع“I‚ئ‚µ‚½ژè–@‚إ‚ح‚ ‚è‚ـ‚¹‚ٌ‚ھپCٹeƒ†ƒjƒbƒg‚ةٹ„‚è•t‚¯‚ç‚ꂽ“ü—حƒfپ[ƒ^ƒOƒ‹پ[ƒv‚ًƒNƒ‰ƒXƒ^‚ئ‚µ‚ؤ‚ف‚ب‚µ‚ؤˆµ‚¤ژ–‚ھ‚إ‚«‚ـ‚·پB‚ـ‚½ٹeƒOƒ‹پ[ƒv‚ج—قژ—“x‚ھ‹£چ‡‘w‚جڈم‚إ‚ج‚QژںŒ³“I‚ب‹——£‚ئ‚µ‚ؤژ‹ٹo‰»‚إ‚«‚邽‚ك,‹³ژt–³‚µƒfپ[ƒ^‚ج”Œ©“I‚بٹwڈK‚ة‚à—LŒّ‚إ‚·پB پ@گ}2‚ةژہچغ‚ةژŒn—ٌ‹Cڈغ‰و‘œ‚ة‘خ‚µ‚ؤ‚جٹwڈK‚جŒ‹‰تپC“¾‚ç‚ꂽ‹£چ‡‘w‚جٹeƒ†ƒjƒbƒg‚ة‘م•\“I‚ب‰و‘œ‚ً“\•t‚¯‚½ƒ}ƒbƒv‚ًژ¦‚µ‚ـ‚·پB‹£چ‡‘w‚ج‚QژںŒ³“I‚بƒ}ƒbƒvڈم‚ة“ء’¥‚جˆظ‚ب‚éƒNƒ‰ƒXƒ^‚ھ“ء’¥‚ة‰‚¶‚ؤکA‘±“I‚ة•ھ•z‚µ‚ؤ‚¢‚邱‚ئ‚ھ‚ي‚©‚è‚ـ‚·پB‚ب‚¨پC“ء‚ةƒNƒ‰ƒXƒ^ٹش‚جٹضŒW‚ًڈع‚µ‚•]‰؟‚·‚é•K—v‚ھ‚ب‚¢‚ج‚إ‚ ‚ê‚خپC‘و‚Q‰ٌ‚إڈذ‰î‚µ‚½ k-means –@‚ب‚ا‚جƒNƒ‰ƒXƒ^ƒٹƒ“ƒOژè–@‚ًژg—p‚·‚éژ–‚à‰آ”\‚إ‚·پB
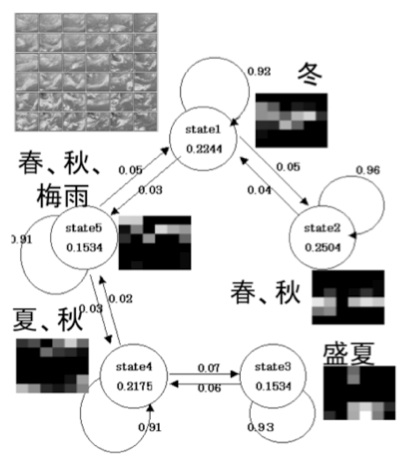
2.2 ‰B‚êƒ}ƒ‹ƒRƒtƒ‚ƒfƒ‹‚ة‚و‚é‹Gگك•د“®‚جƒ‚ƒfƒ‹‰» پ@‘Oگك‚إ“¾‚ç‚ꂽƒNƒ‰ƒXƒ^ƒ‰ƒxƒ‹‚جژŒn—ٌ‚ة‘خ‚µ‚ؤپC‚³‚ç‚ة•ت‚جŒ`‚جژٹش•د“®ƒpƒ^پ[ƒ“‚ً’ٹڈo‚·‚邱‚ئ‚ًچl‚¦‚ؤ‚ف‚ـ‚·پBگ}‚Q‚ة‚¨‚¢‚ؤ“¾‚ç‚ꂽ‰و‘œƒNƒ‰ƒXƒ^‚ج’†گg‚ً’²‚ׂé‚ئپCپg‰ؤ‚جڈI‚ي‚è‚ج‘ن•—‚ج‰و‘œپhپCپg”~‰Jٹْ‚ج‘Oگü‚ج”’B‚µ‚½‰و‘œپhپC‚ئ‚¢‚ء‚½‚و‚¤‚ةپC‰و‘œ‚ج“ء’¥‚ئ”wŒم‚ة‚ ‚éڈَ‘شپi‹Gگك‚ة‘ٹ“–پj‚ھ–§گع‚بŒ‹‚ر‚آ‚«‚ً‚à‚ء‚ؤ‚¢‚邱‚ئ‚ھ—\‘z‚³‚ê‚ـ‚·پB پ@‚±‚ج”wŒم‚ة‰B‚ê‚ؤ‚¢‚éڈَ‘ش‚ة’…–ع‚µ‚½‰B‚êƒ}ƒ‹ƒRƒtƒ‚ƒfƒ‹ (Hidden Markov Model: HMM) [5] ‚حٹm—¦ƒ‚ƒfƒ‹‚ج‚Pژي‚إ‚ ‚èپC‰¹گ؛”Fژ¯پCژ©‘RŒ¾Œêڈˆ—‚ب‚ا‚ةچL‚‰—p‚³‚ê‚ؤ‚¢‚ـ‚·پBHMM ‚حٹm—¦“I‚ة‘Jˆع‚·‚éڈَ‘شڈWچ‡پiƒ}ƒ‹ƒRƒtƒ‚ƒfƒ‹پj‚ئپCٹeڈَ‘ش‚ة‘خ‚·‚éٹm—¦“I‚ب‹Lچ†ڈo—ح‚©‚çچ\گ¬‚³‚ê‚ـ‚·پBٹد‘ھ‚إ‚«‚é‚ج‚ح‹Lچ†ڈo—حŒn—ٌ‚ج‚ف‚إپC”wŒم‚جڈَ‘ش‘JˆعŒn—ٌ‚ح’¼گع“I‚ة‚حŒ©‚邱‚ئ‚ھ‚إ‚«‚ب‚¢‚½‚كپCپg‰B‚êپg‚ئ‚¢‚¤Œ¾—t‚ھژè–@–¼‚ةٹ¥‚³‚ê‚ؤ‚¢‚ـ‚·پBHMM ‚إ‚حپC‚ ‚é‹Lچ†Œn—ٌ‚ھ—^‚¦‚ç‚ꂽ‚ئ‚«پC‚»‚ꂼ‚ê‚ج‹Lچ†‚ھگ¶گ¬ژ‚جڈَ‘ش‚âپCژں‚جژچڈ‚جڈَ‘ش‚âڈo—ح‹Lچ†‚ًگ„’è‚·‚邱‚ئ‚à‚إ‚«‚ـ‚·پB پ@چ،‰ٌ‚ج–â‘è‚إ‚حپCƒNƒ‰ƒXƒ^ƒ‰ƒxƒ‹پi‰و‘œƒ^ƒCƒvپj‚ھپg‹Lچ†Œn—ٌپhپC‚»‚ج”wŒم‚ة‚ ‚é‚ب‚ٌ‚ç‚©‚ج‹Gگك‚ة‘ٹ“–‚·‚é‚و‚¤‚ب‚à‚ج‚ھپgڈَ‘شپg‚ئ‘z’è‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB پ@ƒ‚ƒfƒٹƒ“ƒO‚ة‚ ‚½‚ء‚ؤ‚حپC‹Lچ†Œn—ٌ‚¾‚¯‚©‚çپCڈَ‘شٹش‚ج‘Jˆعٹm—¦پCٹeڈَ‘ش‚إ‚ج‹Lچ†‚جگ¶گ¬ٹm—¦‚ب‚ا‚جƒ‚ƒfƒ‹ƒpƒ‰ƒپپ[ƒ^‚ًگ„’肵‚ـ‚·پBڈَ‘ش‚جگ”‚حٹù’m‚إ‚ ‚é•K—v‚ھ‚ ‚è‚ـ‚·‚ھپCڈَ‘شگ”‚ھ–¢’m‚جڈêچ‡پC•،گ”‚جڈَ‘شگ”‚ة‘خ‚·‚éژژچsŒ‹‰ت‚ً”نٹr‚·‚邱‚ئ‚ة‚و‚ء‚ؤپC“Kگط‚بڈَ‘شگ”‚ً”Œ©‚µ‚ب‚¯‚ê‚خ‚ب‚è‚ـ‚¹‚ٌپB پ@گ} 3 ‚ة 4 ”N•ھ‚جژŒn—ٌ‹Cڈغ‰qگ¯‰و‘œ‚ة‘خ‚µ‚ؤ“¾‚ç‚ꂽ‰B‚êƒ}ƒ‹ƒRƒtƒ‚ƒfƒ‹‚ًژ¦‚µ‚ـ‚· [6]پB‚±‚±‚إپC‰B‚ꂽڈَ‘ش‚جگ”‚ة‚آ‚¢‚ؤ‚حچإڈ‰‚©‚çڈيژ¯“I‚ب‹Gگك‚جگ”‚إ‚ ‚éپg4پh‚ئ‚ح‚¹‚¸پC2-8 ‚ج”حˆح‚إژژچs‚µپCڈî•ٌ—تٹîڈ€‚ً‚à‚ئ‚ةچإ“K‰ً‚ئ‚µ‚ؤڈَ‘شگ”5‚ً‘I‚ر‚ـ‚µ‚½پB
پ@گ}3‚ة‚حٹeڈَ‘ش‚ج”گ¶•p“xپC‘Jˆعٹm—¦‚ھƒOƒ‰ƒt‚ئ‚ئ‚à‚ةگ”’l‚إژ¦‚µ‚ؤ‚¢‚ـ‚·پB—ل‚¦‚خڈَ‘ش2پiڈم’[پj‚ج”گ¶•p“x‚ح 0.2244 ‚إ‚ ‚èپCژں‚جژٹش‚ة‚ح 0.92 ‚جٹm—¦‚إ“¯‚¶ڈَ‘ش‚ضپA0.06, 0.03 ‚ئ‚¢‚¤ڈ¬‚³‚¢ٹ„چ‡‚إڈَ‘ش‚PپCڈَ‘ش‚R‚ة‘Jˆع‚µ‚ـ‚·پB‚ب‚¨پAٹeڈَ‘ش‚ة“Y‚¦‚ç‚ꂽƒOƒŒپ[ƒXƒPپ[ƒ‹ƒ}ƒbƒv‚حپC‚»‚جڈَ‘ش‚ة‚¨‚¯‚éƒNƒ‰ƒXƒ^پi‰و‘œƒ^ƒCƒvپj‚ج”گ¶•p“x‚ًگ} 3 چ¶ڈم‚جƒNƒ‰ƒXƒ^‚ج‘م•\‰و‘œƒ}ƒbƒv‚ة‘خ‰‚³‚¹‚ؤ•\‚µ‚ؤ‚¢‚ـ‚·پB‚±‚جƒJƒ‰پ[ƒ}ƒbƒv‚ئپCڈَ‘ش‚ج”گ¶ژٹْ‚ج”نٹr‚©‚çپCٹeڈَ‘ش‚ةˆس–،•t‚¯‚·‚é‚ئپC{“~}پC{ڈtپCڈHپC”~‰J}, {ڈtپCڈH}پC{‰ؤپCڈH}پC{گ·‰ؤ}‚ئ‚ب‚è‚ـ‚·پB پ@‚ـ‚½پC‚±‚جŒ‹‰ت‚©‚çٹeڈَ‘ش‚حˆہ’è‚إ‚ي‚¸‚©‚بٹm—¦‚إƒ`ƒFپ[ƒ“ڈَ‚ة‘Jˆع‚·‚邱‚ئ‚âپCڈt‚âڈH‚جڈَ‘ش‚ھ2-3ژي—ق‚ة•ھ‚©‚ê‚邱‚ئپCگ^“~‚©‚ç‚جژه—v‚ب‘Jˆعگو‚ھ2ژي—ق‚ ‚é‚ج‚ة‘خ‚µ‚ؤپCگ·‰ؤ‚©‚ç‚جژه—v‚ب‘Jˆعگو‚حˆê‚آ‚µ‚©‚ب‚¢پC‚ئ‚¢‚ء‚½‹»–،گ[‚¢’mŒ©‚ھ“¾‚ç‚ê‚ـ‚·پB‚±‚¤‚µ‚½ژè–@‚حپCژٹش‚ئ‚ئ‚à‚ة•د“®‚·‚éƒXƒyƒNƒgƒ‹‚ج•ھگح‚ب‚ا‚ة‚à“K—p‚ج‰آ”\گ«‚ھ‚ ‚é‚ئچl‚¦‚ç‚ê‚ـ‚·پB 2.3 ‰_‰ٍ‚جژ©“®’ٹڈo‚ئ’اگص پ@‚³‚ç‚ةژ‹“_‚ً‚©‚¦‚ؤپC‰و‘œ‚ج’†‚ة‚س‚‚ـ‚ê‚éˆê‚آˆê‚آ‚جƒIƒuƒWƒFƒNƒgپi‚±‚جڈêچ‡‚ح‰_‰ٍپj‚ة’چ–ع‚µ‚ؤ‚»‚جڈî•ٌ‚©‚çژ‹َٹش•د“®ƒpƒ^پ[ƒ“‚ً’ٹڈo‚·‚é–â‘è‚ًچl‚¦‚ؤ‚ف‚ـ‚·پB‘خڈغ‚جŒ`ڈَ‚ھŒˆ‚ـ‚ء‚ؤ‚¢‚ê‚خپC‚±‚ج–â‘è‚ح‰و‘œ”Fژ¯•ھ–ى‚جƒeƒ“ƒvƒŒپ[ƒgƒ}ƒbƒ`ƒ“ƒO‚âƒgƒ‰ƒbƒLƒ“ƒO‚جژè–@‚إˆµ‚¤ژ–‚ھ‚إ‚«‚ـ‚·پB‚µ‚©‚µپCژو‚èڈo‚·‚ׂ«•¨‘ج‚جپgŒ`ڈَ‚ھ•s’èپhپC‚»‚جپgŒآگ”‚ھ–¢’mپhپC‚ـ‚½پgˆê•”‚حڈd‚ب‚èچ‡‚¤ڈêچ‡‚à‚ ‚éپh‚ئ‚¢‚ء‚½“_‚ھ–â‘è‚ئ‚ب‚è‚ـ‚·پB‚±‚¤‚µ‚½–â‘è‚ً‰ًŒˆ‚·‚é‚ة‚حپCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚إژg—p‚³‚ê‚éٹm—¦–§“x•ھ•z‚جچ¬چ‡•ھ•z‚ة‚و‚郂ƒfƒٹƒ“ƒO [7] ‚ھ—L—p‚إ‚·پBٹm—¦–§“x•ھ•z‚ئ‚µ‚ؤ‘½•د—تگ³‹K•ھ•z‚ً—p‚¢‚邱‚ئ‚ة‚و‚ء‚ؤپCŒX‚«‚â‘ب‰~ڈَ‚ج•ھ•z‚àˆµ‚¤‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB پ@‚S‚ة‹ï‘ج“I‚بŒvژZ‰ك’ِ‚ًژ¦‚µ‚ـ‚·پB‚ـ‚¸‰و‘œ‚ً‰_‚ئ”wŒi‚ة•ھ‚©‚ê‚é‚و‚¤‚ة 2 ’l‰»‚µپC‰_‚ة‘ٹ“–‚·‚éƒsƒNƒZƒ‹‚جچہ•W‚ًƒTƒ“ƒvƒٹƒ“ƒO‚µ‚ؤ‰_“_‚ئ‚µ‚ـ‚·پiگ}‚S’†پjپB‚±‚ج‰_“_‚ج•ھ•z‚ًچ¬چ‡‘½•د—تگ³‹K•ھ•z‚إƒ‚ƒfƒ‹‰»‚µپCƒ‚ƒfƒ‹‚جƒpƒ‰ƒپپ[ƒ^‚ًگ„’肵‚ـ‚·پiگ}‚S‰EپjپBƒpƒ‰ƒپپ[ƒ^‚جگ„’è‚ة‚ح EM ƒAƒ‹ƒSƒٹƒYƒ€ [5] ‚ًژg—p‚·‚邱‚ئ‚ھˆê”ت“I‚إ‚·پB‚ب‚¨پCگ¬•ھگ”‚ھ•s’è‚جڈêچ‡پC‘½گ”‚جƒPپ[ƒX‚ة‚آ‚¢‚ؤژژچs‚µ‚ؤچإ“K‚بŒ‹‰ت‚ً‘I‘ً‚·‚邱‚ئ‚ھ•K—v‚ة‚ب‚è‚ـ‚·پB
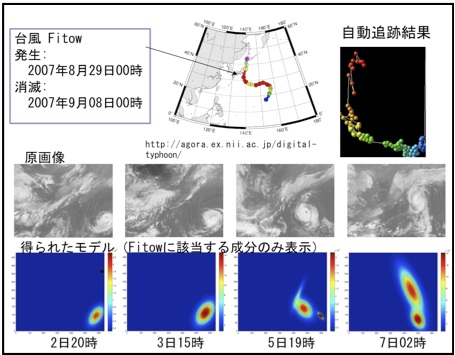
پ@‚ـ‚½ژŒn—ٌ‰و‘œ‚إ‚ج‰_‰ٍ‚ج’اگص‚ة‚حپC‘O‚جژچڈ‚ج‰ً‚ةپCڈء–إ‚âپCگ¶گ¬‚ًچl—¶‚ة“ü‚ê‚ؤ‚خ‚ç‚آ‚«‚ًژ‚½‚¹‚½ڈ‰ٹْ’l‚ً“±“ü‚·‚邱‚ئ‚ة‚و‚ء‚ؤ‘خڈˆ‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پBگ}‚T‚ة‚±‚جژè–@‚إژہژ{‚³‚ꂽ‘ن•—‚ج’اگصŒ‹‰ت‚ًژ¦‚µ‚ـ‚·[8]پB‚±‚±‚إ‚حپAˆê‚آ‚ج‰_‰ٍ‚ج’اگص‚ئ‚ئ‚à‚ة”hگ¶‚µ‚ؤ•ھ—£‚·‚éگ¬•ھ‚جژو“¾‚àژہŒ»‚إ‚«‚ؤ‚¢‚邱‚ئ‚ھٹm”F‚إ‚«‚ـ‚·پB
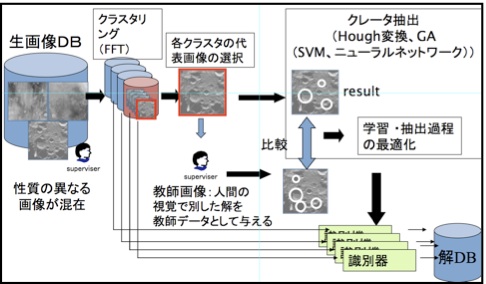
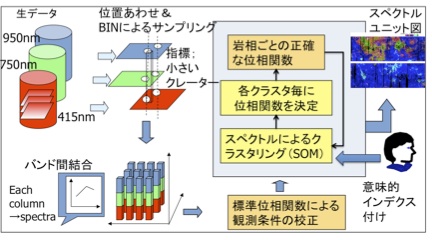
پ@‚±‚ج‚و‚¤‚ة‚µ‚ؤ’ٹڈo‚³‚ꂽƒIƒuƒWƒFƒNƒg‚جڈî•ٌ‚ةپC‚³‚ç‚ة‰_ژ©‘ج‚جƒpƒ^پ[ƒ“‚ج“ء’¥پiƒeƒNƒXƒ`ƒƒ‚ب‚اپj‚â‚»‚ج‘¼‚جٹد‘ھ’l‚ً‘g‚فچ‡‚ي‚¹‚邱‚ئ‚ة‚و‚ء‚ؤپCچ‚ژں‚ج’mژ¯”Œ©‚جژx‰‡‚ًچs‚¤‚±‚ئ‚ھ‚إ‚«‚é‚ئٹْ‘ز‚إ‚«‚ـ‚·پB‚±‚ج‚و‚¤‚بژè–@‚حپC‘ه—ت‰و‘œ‚©‚ç‚ج–¢’m“V‘ج‚جژ©“®’ٹڈo‚â‚»‚جژٹش•د“®‚ج’اگصپC—¬‘جƒVƒ~ƒ…ƒŒپ[ƒVƒ‡ƒ“‚جŒ‹‰ت‚ج—‰ً‚ة‚à‰—p‰آ”\‚ئچl‚¦‚ç‚ê‚ـ‚·پB ‚RپDکfگ¯‰و‘œ‚ض‚ج“K—p—ل پ@ژں‚ةŒژ‚ج‰و‘œ‚ة‘خ‚·‚é“K—p—ل‚ًژ¦‚µ‚ـ‚·پB‚±‚±‚إ‚حکfگ¯‰و‘œ‚©‚ç‚جƒNƒŒپ[ƒ^پ[’nŒ`‚ج’ٹڈoپC‚¨‚و‚رƒ}ƒ‹ƒ`ƒoƒ“ƒh‰و‘œ‚©‚ç‚ج’nژ؟گ}‚جچىگ¬‚ة‚آ‚¢‚ؤڈذ‰î‚µ‚ـ‚·پB 3.1کfگ¯‰و‘œ‚©‚ç‚جƒNƒŒپ[ƒ^پ[’nŒ`‚ج’ٹڈo پ@‰و‘œ‚©‚ç‚جƒNƒŒپ[ƒ^پ[‚â‰خژR‚ب‚ا‚ج“ء’¥’nŒ`‚ج’ٹڈo‚ة‚حپC‰و‘œ”Fژ¯‚جژè–@‚ج‘¼‚ةپCگ³—ل‚ئ•‰—لپiٹشˆل‚ء‚½ژ–—لپj‚جڈWچ‡‚©‚ç‹@ٹBٹwڈK‚جژè–@‚ة‚و‚ء‚ؤ”Fژ¯ٹي‚ًچىگ¬‚·‚é‚ئ‚¢‚¤ƒAƒvƒچپ[ƒ`‚ھŒں“¢‚³‚ê‚ؤ‚«‚ـ‚µ‚½پB‚µ‚©‚µپC“ء‚ةŒُٹw“I‚ة“¾‚ç‚ꂽ‰و‘œ‚حڈئ–¾ڈًŒڈ‚ج‰e‹؟‚ً‘ه‚«‚ژَ‚¯پC‚ ‚éڈًŒڈ‚إچىگ¬‚³‚ꂽ”Fژ¯ٹي‚ھ‘¼‚جڈًŒڈ‚إ‚àگ³‚µ‚‹@”\‚·‚é‚ئ‚حŒہ‚ç‚ب‚¢پC‚ئ‚¢‚¤–â‘è‚ھ‚ ‚è‚ـ‚µ‚½پB پ@گ}‚U‚ةژ¦‚·کfگ¯‰و‘œ‚©‚ç‚جƒNƒŒپ[ƒ^پ[’ٹڈoƒVƒXƒeƒ€[9]‚إ‚حپCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO“I‚بژ‹“_‚ًژو‚è“ü‚êپC‚ـ‚¸‰و‘œڈWچ‡‚ً‰و‘œ‚ج“ء’¥‚ة‚و‚ء‚ؤƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚µ‚ؤƒOƒ‹پ[ƒv‰»‚µپCٹeƒOƒ‹پ[ƒv‚ة‘خ‚µ‚ؤ”Fژ¯ٹي‚ًƒ`ƒ…پ[ƒjƒ“ƒO‚·‚éژè–@‚ً’ٌˆؤ‚µ‚ـ‚µ‚½پB‚±‚ج‚و‚¤‚ةڈ]—ˆ•ھگح‚ھ“‚©‚ء‚½ژè–@‚ة‚àپCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO“I‚بٹد“_‚©‚çپCƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ة‚و‚ء‚ؤژ©“®“I‚بƒOƒ‹پ[ƒsƒ“ƒO‚ًچs‚¤‚ئ‚¢‚¤ƒvƒچƒZƒX‚ً“±“ü‚·‚邱‚ئ‚ة‚و‚ء‚ؤپC–â‘è‚ًŒn““I‚ةˆµ‚¢‚â‚·‚‚·‚邱‚ئ‚ھ‚إ‚«‚ـ‚·پB
3.2 ƒ}ƒ‹ƒ`ƒoƒ“ƒh‰و‘œ‚©‚ç‚جچZگ³‚جژ©“®‰»‚ئ’nژ؟گ}‚جچىگ¬ پ@‹ك”NپC‚©‚®‚âپCChandrayaan‚ب‚ا‚ج’Tچ¸‹@‚ة‚و‚ء‚ؤŒژ‚جƒ}ƒ‹ƒ`ƒXƒyƒNƒgƒ‹‰و‘œپCکA‘±ƒXƒyƒNƒgƒ‹‚ھ‘±پX‚ئژو“¾‚³‚ê‚ؤ‚«‚ؤ‚¢‚ـ‚·پB‚±‚ê‚ç‚جƒXƒyƒNƒgƒ‹ٹد‘ھ‚ج–ع“I‚ح•\–ت‚ج•¨ژ؟•ھ•z‚ً’m‚邱‚ئ‚إ‚·‚ھپC‚»‚ج‚½‚ك‚ة‚حٹد‘ھڈًŒڈ‚ج‰e‹؟‚ًژو‚èڈœ‚‚½‚ك‚ةˆت‘ٹٹضگ”‚ب‚ا‚ً—p‚¢‚½چZگ³‚ھ•K—v‚إ‚·پB‚µ‚©‚µپCˆت‘ٹٹضگ”‚ح—ک_‚âٹد‘ھ‚©‚畨ژ؟ˆث‘¶گ«‚ھ‚ ‚邱‚ئ‚ھژw“E‚³‚ê‚ؤ‚¢‚ـ‚µ‚½پB پ@‰،“c (2003) [10] ‚حپC‚±‚ج–â‘è‚ة‘خ‚µ‚ؤپC•Wڈ€“IچZگ³ژ®‚ة‚و‚éچZگ³‚إ‰¼چZگ³‚µ‚½ƒXƒyƒNƒgƒ‹‚ة‘خ‚·‚éƒNƒ‰ƒXƒ^ƒٹƒ“ƒOپCƒNƒ‰ƒXƒ^‚²‚ئ‚جچZگ³ژ®‚جŒˆ’è‚ئ‚¢‚¤‰ك’ِ‚ًŒJ‚è•ش‚·‚±‚ئ‚ة‚و‚ء‚ؤپC•¨ژ؟ƒOƒ‹پ[ƒv‚²‚ئ‚جچZگ³‹بگü‚ئ•¨ژ؟•ھ•zگ}‚ً“¯ژ‚ةژو“¾‚·‚éژè–@‚ً’ٌˆؤ‚µ‚ـ‚µ‚½پBگ} 7 ‚ة‚»‚جٹT”Oگ}‚ًژ¦‚µ‚ـ‚·پB‚±‚جژè–@‚جƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ج•”•ھ‚ة‚ح‘Oگك‚إڈذ‰î‚µ‚½ SOM ‚ھژg—p‚³‚ê‚ؤ‚¢‚ـ‚·پB‚±‚جژ–—ل‚àڈ]—ˆگl‚ة‚و‚é‘€چى‚إ‚ح–c‘ه‚بژٹش‚ً—v‚µ‚ؤپCŒ»ژہ“I‚ة•s‰آ”\‚إ‚ ‚ء‚½چى‹ئ‚ھپCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جژ‹“_‚©‚çپCƒNƒ‰ƒXƒ^ƒٹƒ“ƒO‚ج‰ك’ِ‚ھ“±“ü‚³‚ꂽ‚±‚ئ‚ة‚و‚ء‚ؤ‰ًŒˆ‚³‚ꂤ‚邱‚ئ‚ھژ¦‚µ‚½—ل‚ئ‚¢‚¤‚±‚ئ‚ھ‚إ‚«‚ـ‚·پB
‚SپD‚¨‚ي‚è‚ة پ@چ،‰ٌ‚حژŒn—ٌ‹Cڈغ‰و‘œ‚ة‚آ‚¢‚ؤ‚RژيپCکfگ¯‰و‘œ‚ة‚آ‚¢‚ؤ‚Qژي‚ج—ل‚ً‰qگ¯ƒfپ[ƒ^‚ض‚جƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جٹˆ—p—ل‚ئ‚µ‚ؤڈذ‰î‚µ‚ـ‚µ‚½پBƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جکg‘g‚ف‚إˆµ‚ي‚ê‚éژè–@‚ة‚حپCچ،‰ٌژو‚è‚ ‚°‚½ژè–@‚ةŒہ‚炸‘½—l‚بژè–@‚ھٹـ‚ـ‚êپC‘ه—تƒfپ[ƒ^‚ًˆµ‚¤Œ¤‹†ژز‚ة‚ئ‚ء‚ؤ‚ح‚±‚ê‚ç‚جژè–@ژ©‘ج‚ھ•َ‚جژR‚ئ‚¢‚¦‚ـ‚·پB پ@‚ئ‚ح‚¢‚¦پCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚â‹@ٹBٹwڈK‚حƒRƒ“ƒsƒ…پ[ƒ^‚ج”ٌگê–ه‰ئ‚ة‚ئ‚ء‚ؤ‚ح‚ـ‚¾•~‹ڈ‚جچ‚‚¢—جˆو‚إ—L‚é‚و‚¤‚ةŒ©‚¦‚ـ‚·پBˆê•ûپCƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚جگ¬Œ÷‚ة‚حگê–ه‰ئ‚ج’mŒ©‚ھ•Kگ{‚إ‚ ‚èپCƒfپ[ƒ^‚ًˆµ‚¤•ھ–ى‚جگê–ه‰ئ‚ئƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚ب‚ا‚جگê–ه‰ئ‚ج‹ظ–§‚بکAŒg‚ھڈd—v‚ة‚ب‚è‚ـ‚·پB پ@ƒAƒپƒٹƒJ‚جƒWƒFƒbƒgگ„گiŒ¤‹†ڈٹ‚ة‚ح The Machine Learning and Instrument Autonomy (MLIA) Group [11] ‚ھ‘¶چف‚µ‚ؤپC‚±‚¤‚µ‚½•ھ–ى‚جŒ¤‹†‚ًچs‚ء‚ؤ‚¢‚ـ‚·پB‘ه—تƒfپ[ƒ^‚جƒAپ[ƒJƒCƒu‚©‚ç—ک—p‚ةŒü‚©‚¤—¬‚ê‚ج‚ب‚©‚إ‚حپC‚±‚¤‚µ‚½•ھ–ى‚جگê–ه‚جŒ¤‹†ˆُ‚âڈي‹خ‚جƒXƒ^ƒbƒt‚ًŒ}‚¦‚½‚èپCٹO•”‚جŒ¤‹†‹@ٹض‚ئ‚جکAŒg‚ً‘gگD“I‚ةŒ`گ¬‚µ‚½‚è‚·‚éژ–‚àڈd—v‚©‚à‚µ‚ê‚ـ‚¹‚ٌپBچإŒم‚ةچ،‰ٌ‚جکAچع‚ً’ت‚¶‚ؤڈ‚µ‚إ‚àƒfپ[ƒ^ƒ}ƒCƒjƒ“ƒO‚ة‚آ‚¢‚ؤ‹»–،‚ًژ‚ء‚ؤ‚¢‚½‚¾‚¯‚ـ‚µ‚½‚çچK‚¢‚إ‚·پB •¶Œ£“™ [1] چ‚’m‘هٹw‹Cڈغڈî•ٌ http://weather.is.kochi-u.ac.jp/
|
|
||||||||||||