|
様々な望遠鏡や観測装置で観測された宇宙の姿は、世界中の計算機の中に数値データ(これを観測された「数値宇宙」と呼ぶ)として記録されている。従って、これまでに観測された宇宙は計算機ネットワークを通して再観測を行うことができる。この数値宇宙を観測する望遠鏡を仮想望遠鏡(Virtual Telescope)といい、数値宇宙の一部と仮想望遠鏡をもつ天文台を仮想天文台(VO: Virtual Observatory)という。数値宇宙は、スローン・デジタル・スカイ・サーベイ(SDSS)のように専用望遠鏡による大規模なサーベイ観測が盛んに行われるようになり急速に拡大している。これら多波長のサーベイ観測データの比較研究によって、これまで見つけることが難しかった希な天体が発見できるようになり、データベース天文学という新たな天文学が誕生した。VO では観測波長に依存しない仮想望遠鏡によって容易に多波長の観測データの比較研究が行える。VO はデータベース天文学のための強力な道具であり、これによってデータベース天文学が発展すると期待している。
国立天文台では日本版 VO (JVO) の開発を行っており、仮想天文台とデータベース天文学については、天文月報 2002年 6,7 月号のデータベース天文学特集で紹介されている。これらの記事はJVOのホームページ (http://jvo.nao.ac.jp/) に掲載されているので参照されたい。ここでは、国立天文台データベース天文学推進室で昨年から開発を進めている JVO プロトタイプについて紹介する。
|
|
JVO の最初のプロトタイプを開発するにあたり、
の2点を目標にした。概念設計にあたり、JVO を使って何をするのか実際の例(Use Case)を数え上げる。例えば、「2つ以上のバンドで取られている領域からバンド/カラーごとの star count を求め銀河系のモデルと比較する」といったものである。この Use Case の実際の処理を机上でシミュレーションして必要な処理を洗い出す。例の処理は、
- 2つ以上のバンドで撮られている領域のリストアップ
- それぞれのデータの重なった領域の切り出し
- それぞれのデータでの天体検出
- 検出天体リストでの星、銀河の分類
- 各領域での天体リストのクロスマッチ
- 天体リストから star count へ
といった手順に分解できる。この処理は大きく分けてデータベース機能と画像処理機能の2つに大別できる。VO は地理的に分散した天文データベース/データアーカイブを対象にするので、分散を考慮しなければならないのはデータベース機能である。中でも複数のデータベースにまたがる検索が本質的である。そこで、VO の分散データベースへの問い合わせ言語として JVO Query Language を定義し、RDB (Relational Data Base) を用いて Subaru と 2 MASS のデータベースを構築し、その有効性を実証することを第1の目的にした。
天文データベースは世界中に分散しているため、インターネット接続された計算機間での連携を実現するミドルウェアが必要となる。世界の VO が連携するためにミドルウェアとして標準的な技術を使うことが重要である。現在ミドルウェアとして有望なのは唯一 GRID であり、世界の VO プロジェクトでも GRID が採用されている。GRID はGlobal Grid Forum(http://www.globalgridforum.org/L_About/about.htm 参照)で規格が制定されていれるが、昨年2月に GRID に Web service の機能を加える大きな拡張が提案された。 プロトタイプには GRID 環境を実現するために Globus Toolkit version 2 を採用し、GRID が実際に機能することを確認し機能を評価することを第2の目的とした。
|
|
VO では様々な望遠鏡や観測装置で取得された観測データがアーカイブに保存され、データベース管理されていることを想定している。実際に使用されているデータベースシステム (DBMS) は RDB が一般的である。どのようなデータベースシステムが VO として必要かは慎重に検討する必要がある。画像データを扱える OODB (オブジェクト指向データベース)も候補であるが、先に述べた use case を分析した範囲では RDB で対応可能であると判断し、JVO プロトタイプでは RDB を内部システムとして採用することにした。 JVO では単一のインターフェイスで複数のデータサーバからカタログデータ、画像データを取得することができる。JVO システムに対するデータ請求要求を記述するインターフェイス言語となる JVO Query Language の文法として SQL (Structured Query Language) を拡張した。
図1にカタログデータを利用してそれらに対応する画像データを要求する検索の JVO-QL コマンドを示す。説明の詳細は省くが、主な拡張はwhere 節にある。XMATCH 演算子は複数のカタログをクロスマッチすることを意味し、 XMATCH(c1, c2, !c3...) < 3 arcsec [NEAREST | BRIGHTEST | ALL] はc1 と c2 を許容誤差 3秒角の positional matching を行い、さらにそれらのうち c3 には含まれていないものを選択することを意味する。
| create [materialized] view mytable as |
| select |
c1.column1, c2.column1, c2.column2, ..., |
|
d1.BOX(POINT(c1.ra, c1.dec), width1, height1) as BlueImage, ... |
|
c1.column3 / c2.column5 as flux_ratio, c3.*, ... |
| from |
catalog1 c1, catalog2 c2, catalog3 c3, ..., data d1, ... |
| where XMATCH(c1, c2, !c3...) < 3 arcsec [NEAREST | BRIGHTEST | ALL] |
|
and (c1.column1 - c2.column1) < 6.0 mag |
|
and BOX(POINT(ra0, dec0), width0, height0) |
|
and ... |
|
|
図1. JVO-QL コマンドの例(1)
また、(c1.column1 - c2.column1) < 6.0 mag は通常のSQL文と同様の条件式であるが、カタログのメタデータで指定されている単位に基づいて異なるカタログ間での単位変換を行った後に演算、比較を行う。
簡単な例として、図2に2色のデータ(data1とdata2)があってその観測領域が重なっている部分のデータを取得する JVO-QL コマンドを示す。
| select |
X.a, Y.a |
| from |
data1.wavelength1 X, |
|
data2.wavelength2 Y |
| where |
(X.AREA() OVERLAP Y.AREA()) as a |
|
|
図2. JVO-QL コマンドの例(2)
ここで、X.AREA() = data1.wavelength1.AREA() は画像データアーカイブ data1 の波長 wavelength1 のデータがカバーしている領域を表す。
検索結果は International Virtual Observatory のために開発されたカタログデータの標準フォーマットである VOTable (http://cdsweb.u-strasbg.fr/doc/VOTable/参照)で与えられる。
|
|
プロトタイプでは Solaris OS の WS と Linux OS の PC という異機種のハードウェアを組み合わせたテスト環境を用い、DBMS は Oracle と PostgreSQL の 2種類を使った。その他はフリーソフトウェアを使用した。GRID の実装としては Globus toolkit v2 に含まれている OpenSSL (Secure Socket Library)、OpenLDAP (LDAP Server)、wu-ftpd (ftp server) を使用した。Web サービスの機能は Globus toolkit v2 に含まれていないため SOAP (Simple Object Access Protocol) を採用した。
図3に JVO プロトタイプのシステム構成を示す。 利用者は自分の好みの Web Browser で JVO Portal サーバにアクセスする。利用者認証後、JVO のメイン画面が現れる。この画面で JVO-QL で記述した仮想観測命令を JVO コントローラに送る。コントローラは命令を解析し、UDDI Registry を参照して要求されたサービスを提供するサーバを引き当て、各サーバの GSDL (WSDL の GRID 版:サービスのインターフェースが定義されている)を参照して、仮想観測命令の実行手順を作成する。この手順に従い、GRID 経由で各サーバに実行要求を送る。予定されたサーバが何らかの原因で実行に失敗すると、コントローラは同じサービスを提供する別のサーバを探し、それに実行要求を出し直す。これを繰り返し最終的な結果が JVO サーバに出来上がる。
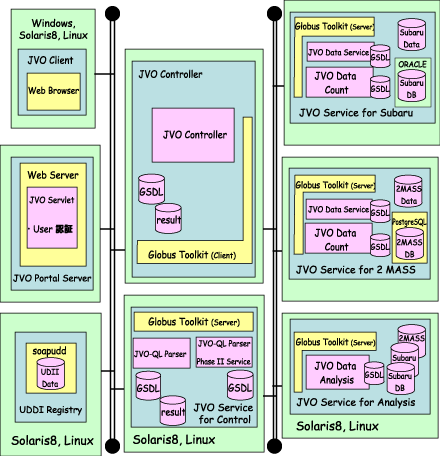
図3 JVOプロトタイプのシステム構成図
このプロトタイプでは DB サーバとして、2MASS のカタログサーバと Subaru-SXDS のカタログ・画像サーバの2種類を実装した。一般に、天文 DB サーバは読み取り専用でデータ検索以外のサービスを期待できない。そのため、カタログの相互比較機能は JVO サーバの一つとして実装した。
|
|
分散したデータベースを JVO-QL により統一的に扱い、複数の独立な DB 上のカタログデータの相互比較を行い、一致した天体の部分画像の取得ができることを JVO プロトタイプによって実証した。またソフトウェア技術の観点からは、GRID 準拠の分散処理システムとして動作することを実証した。ただし、プロトタイプの実装開始時点で利用可能だった GRID 基盤の Globus Toolkit v2 には Web サービス機能がないため、その機能は SOAP で実現した。
大規模カタログの検索やカタログ間の相互比較にかかる処理時間は数秒で終わるものから何時間もかかるものまで予想がつかない。利用者は JVO に対する要求を出したら処理結果を待たずに操作を終了し、必要なときに処理経過を JVO に問い合わせるという使い方が望ましい。JVO プロトタイプでは Web ブラウザを用いてインターネットの世界から GRID の Portal サーバを通して GRID の世界の JVO システムを使うという方式によって、利用者の操作部分と JVO の実際の仕事をするサーバ部分の分離を実現した。
実行性能は GRID を使用しないで既存のサーバクライアント技術でシステムを構築したほうが格段に良いと思われる。プロトタイプではサーバに実行要求を出してから実際に起動されるまで数秒かかる。この性能の悪さは Globus Toolkit に原因がある。GRID サービスの起動時の認証等のオーバーヘッドが一因となっており、起動時の認証を毎回行わず、キャッシュを利用するなどの改善策も知られている。プロトタイプによる GRID の評価としては、実行性能はまだまだ不十分であるが、機能として使えないものではない。
|
